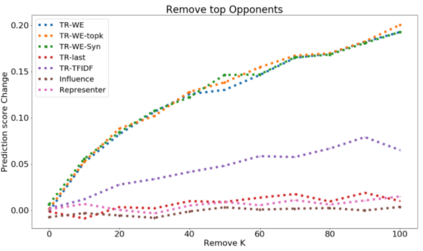
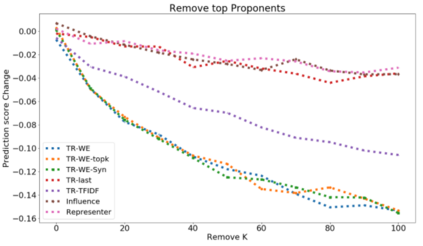
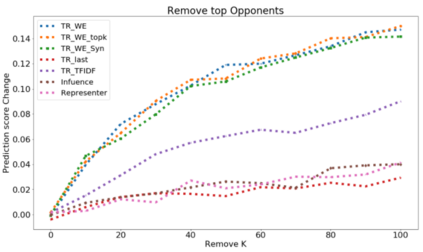
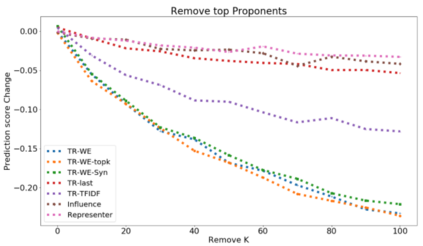
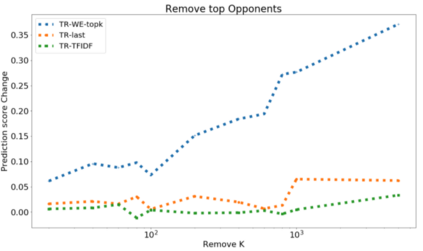
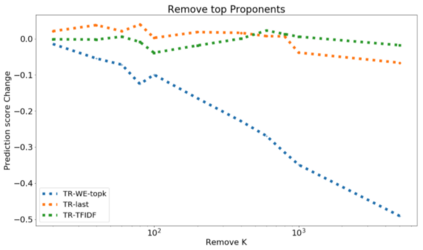
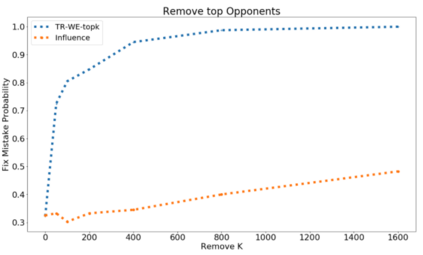
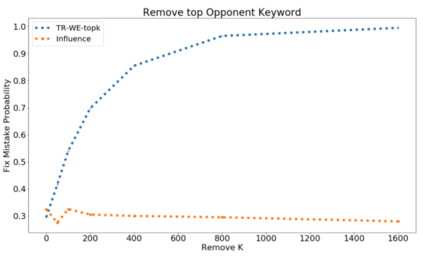
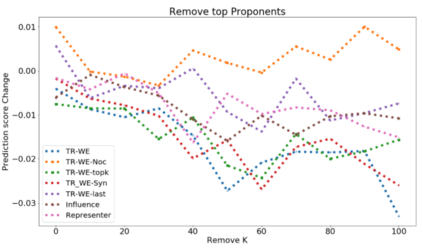
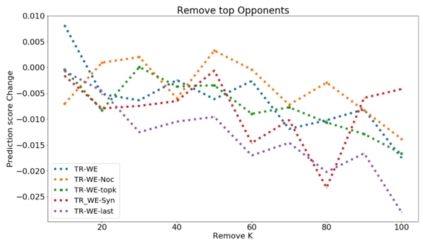
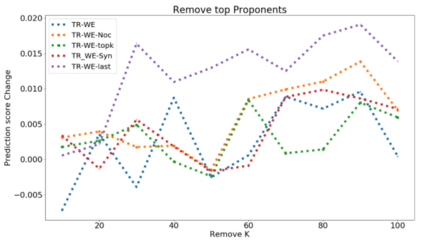
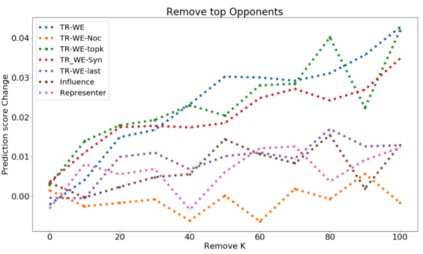
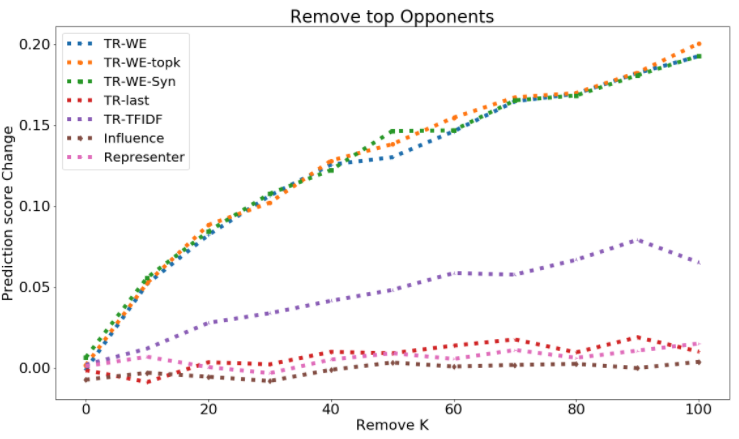
The ability to identify influential training examples enables us to debug training data and explain model behavior. Existing techniques are based on the flow of influence through the model parameters. For large models in NLP applications, it is often computationally infeasible to study this flow through all model parameters, therefore techniques usually pick the last layer of weights. Our first observation is that for classification problems, the last layer is reductive and does not encode sufficient input level information. Deleting influential examples, according to this measure, typically does not change the model's behavior much. We propose a technique called TracIn-WE that modifies a method called TracIn to operate on the word embedding layer instead of the last layer. This could potentially have the opposite concern, that the word embedding layer does not encode sufficient high level information. However, we find that gradients (unlike embeddings) do not suffer from this, possibly because they chain through higher layers. We show that TracIn-WE significantly outperforms other data influence methods applied on the last layer by 4-10 times on the case deletion evaluation on three language classification tasks. In addition, TracIn-WE can produce scores not just at the training data level, but at the word training data level, a further aid in debugging.
翻译:识别有影响力的培训实例的能力使我们能够调试培训数据并解释模型行为。 现有技术基于模型参数的影响流。 对于国家语言平台应用程序中的大型模型, 通常无法通过所有模型参数来研究这种流动, 因此技术通常会选择最后一层的重量。 我们的第一点观察是, 对于分类问题, 最后一层是递减性的, 没有将足够的输入级别信息编码。 根据这项测量, 去除有影响力的示例通常不会大大改变模型的行为。 我们建议一种叫作TracIn- WE的技术, 它将改变名为TracIn的方法, 以在文字嵌入层而不是最后一个层上操作。 这可能会引起相反的关注, 即嵌入层的字不会编码足够的高层次信息。 然而, 我们发现, 梯度( 不喜欢嵌入层) 并不受影响, 可能是因为它们通过更高层次的链条。 我们显示, TracIn- WE 明显地超越了在最后一个层次上应用的其他数据影响方法 。 在三个语言分类任务中, TracInWE 可以进一步生成数据 。 在三个 级别上, 数据培训 的 的等级 数据 。