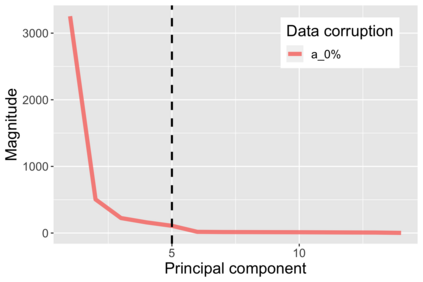
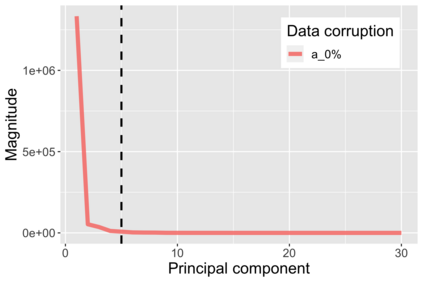
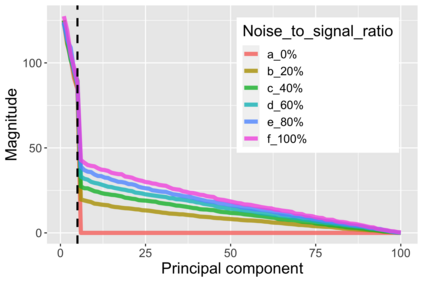
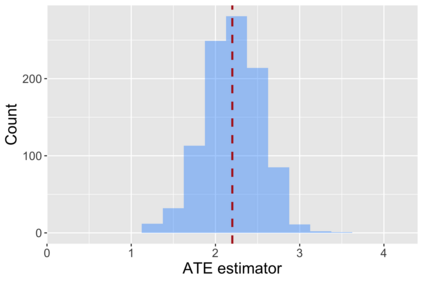
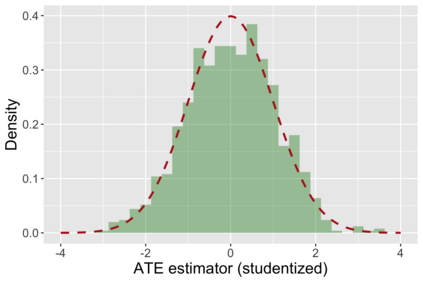
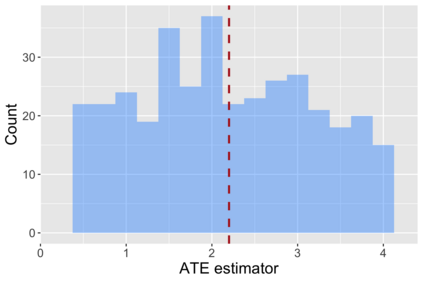
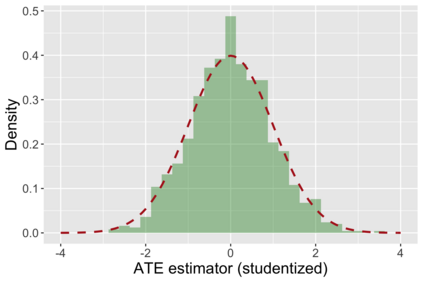
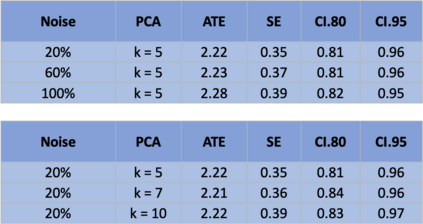
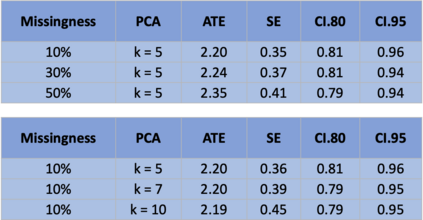
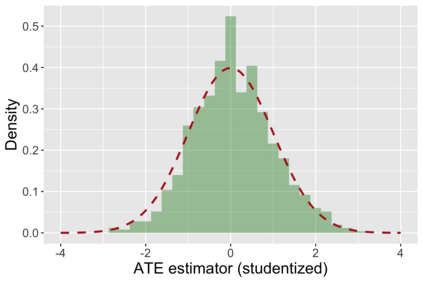
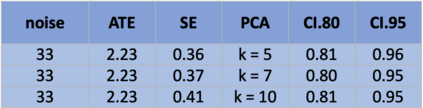
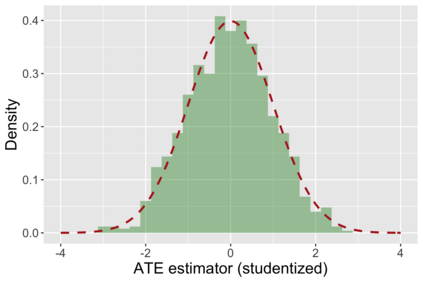
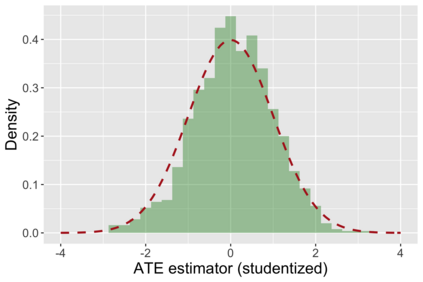
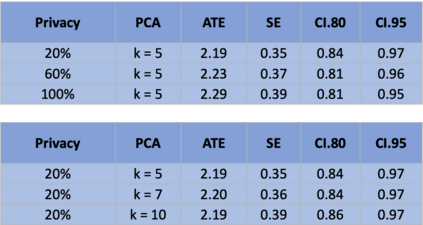
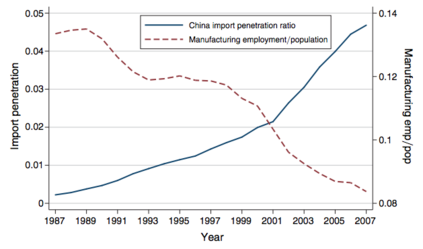
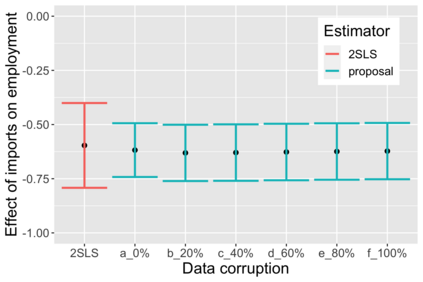
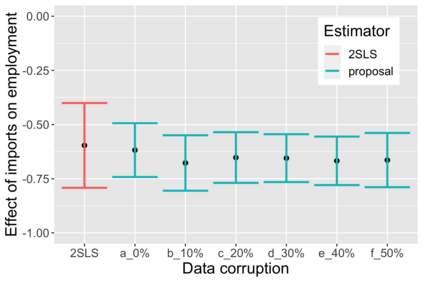
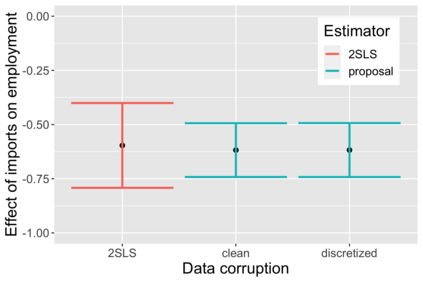
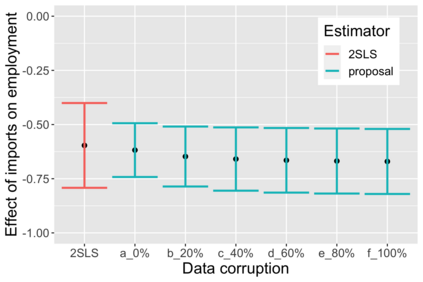
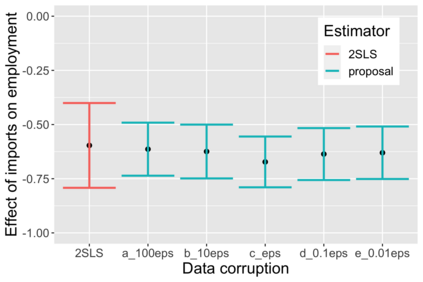
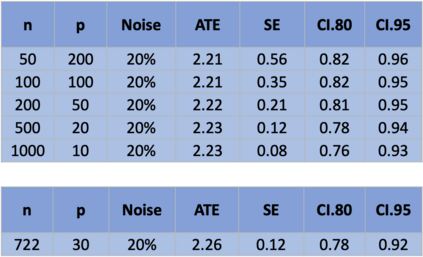
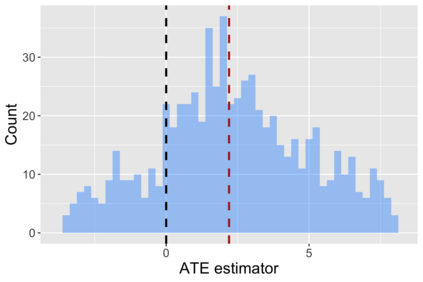
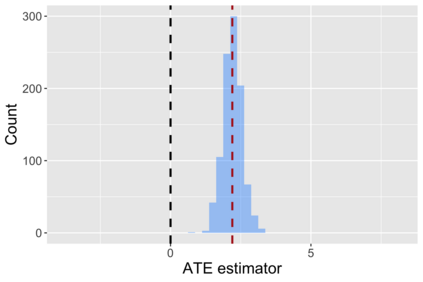
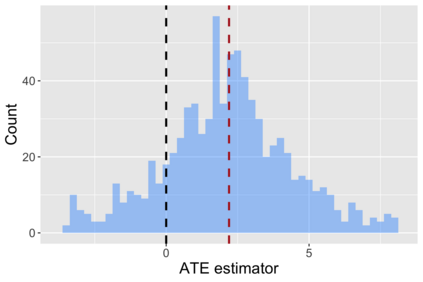
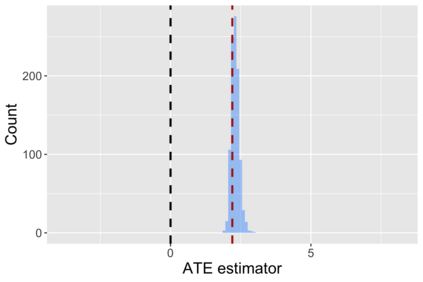
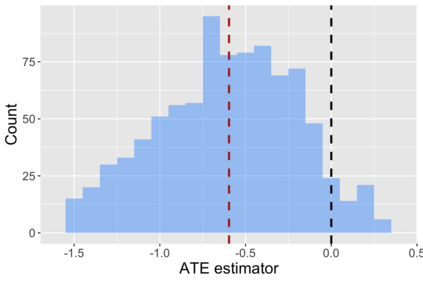
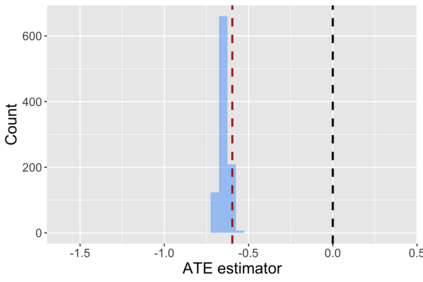
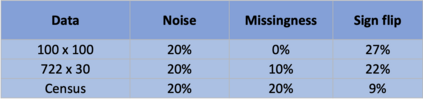
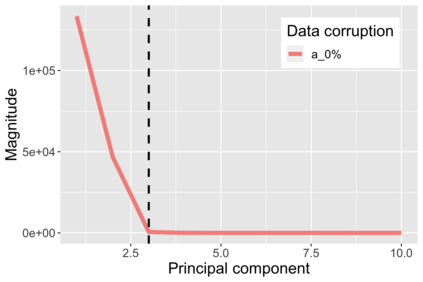
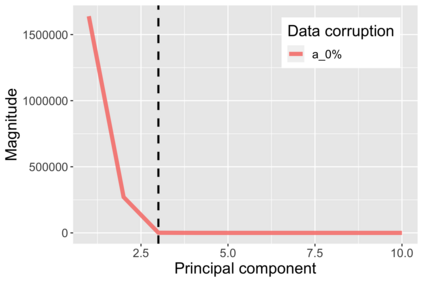
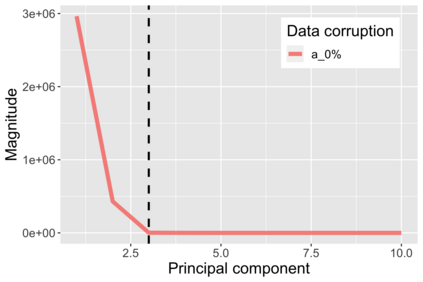
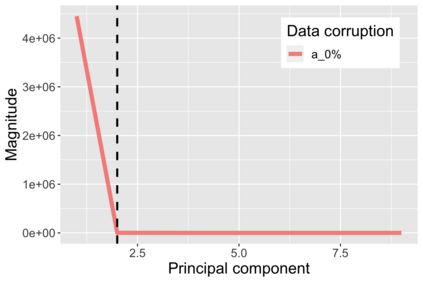
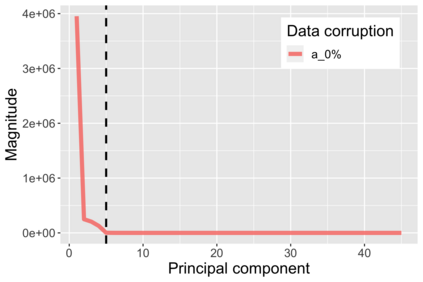
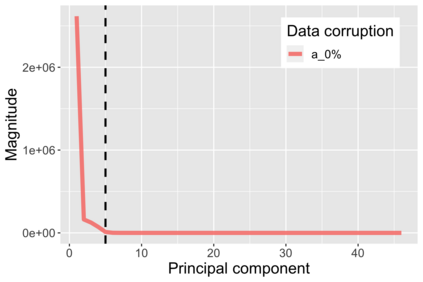
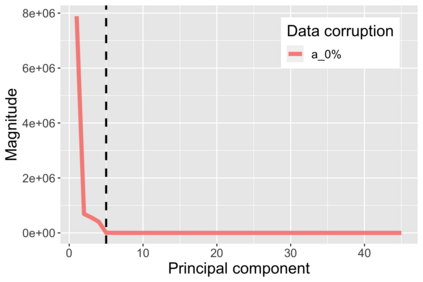
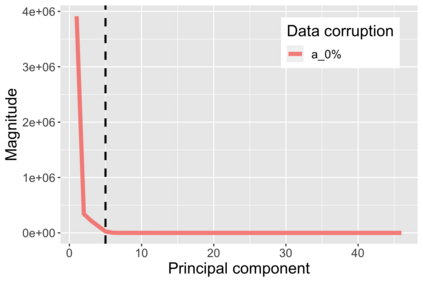
The US Census Bureau will deliberately corrupt data sets derived from the 2020 US Census in an effort to maintain privacy, suggesting a painful trade-off between the privacy of respondents and the precision of economic analysis. To investigate whether this trade-off is inevitable, we formulate a semiparametric model of causal inference with high dimensional corrupted data. We propose a procedure for data cleaning, estimation, and inference with data cleaning-adjusted confidence intervals. We prove consistency, Gaussian approximation, and semiparametric efficiency by finite sample arguments, with a rate of $n^{-1/2}$ for semiparametric estimands that degrades gracefully for nonparametric estimands. Our key assumption is that the true covariates are approximately low rank, which we interpret as approximate repeated measurements and validate in the Census. In our analysis, we provide nonasymptotic theoretical contributions to matrix completion, statistical learning, and semiparametric statistics. Calibrated simulations verify the coverage of our data cleaning-adjusted confidence intervals and demonstrate the relevance of our results for 2020 Census data.
翻译:美国人口普查局将故意腐蚀来自2020年美国人口普查的数据集,以维护隐私,暗示在答复者的隐私和经济分析精确度之间进行痛苦的权衡。为了调查这种权衡是否不可避免,我们用高度腐蚀的数据来制定一个因果推断的半参数模型。我们提出了一个数据清理、估计和推断的程序,用数据清理调整信任间隔来进行计算。我们通过有限的抽样参数来证明一致性、高斯近似值和半参数效率,对非参数估计值而言,半参数估计值降幅为1/2美元。我们的主要假设是,真正的共变体的等级几乎很低,我们在人口普查中将其解释为大约重复测量和验证。我们在分析中为矩阵的完成、统计学习和半参数统计提供了非抽象的理论贡献。经过校准的模拟核查了我们数据清理调整信任间隔的覆盖面,并展示了我们结果对2020年人口普查数据的关联性。