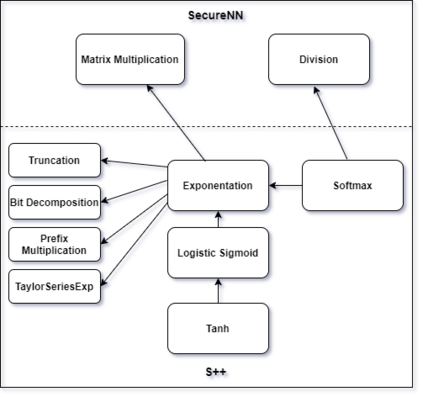
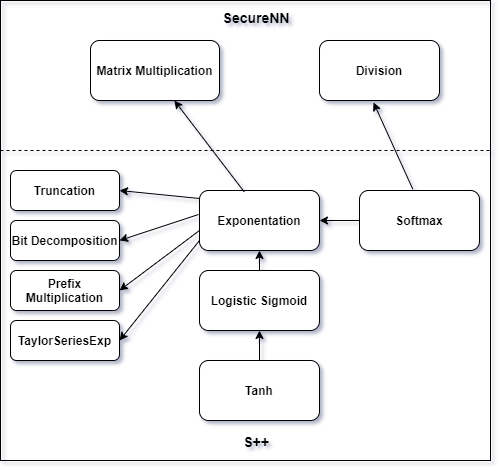
We introduce S++, a simple, robust, and deployable framework for training a neural network (NN) using private data from multiple sources, using secret-shared secure function evaluation. In short, consider a virtual third party to whom every data-holder sends their inputs, and which computes the neural network: in our case, this virtual third party is actually a set of servers which individually learn nothing, even with a malicious (but non-colluding) adversary. Previous work in this area has been limited to just one specific activation function: ReLU, rendering the approach impractical for many use-cases. For the first time, we provide fast and verifiable protocols for all common activation functions and optimize them for running in a secret-shared manner. The ability to quickly, verifiably, and robustly compute exponentiation, softmax, sigmoid, etc., allows us to use previously written NNs without modification, vastly reducing developer effort and complexity of code. In recent times, ReLU has been found to converge much faster and be more computationally efficient as compared to non-linear functions like sigmoid or tanh. However, we argue that it would be remiss not to extend the mechanism to non-linear functions such as the logistic sigmoid, tanh, and softmax that are fundamental due to their ability to express outputs as probabilities and their universal approximation property. Their contribution in RNNs and a few recent advancements also makes them more relevant.
翻译:我们引入了S++,这是一个简单、稳健和可部署的框架,用于培训使用来自多种来源的私人数据的神经网络(NN),使用秘密共享的安全功能评估。简言之,我们考虑一个虚拟第三方,每个数据持有人都向它发送投入,并计算神经网络:在我们的情况下,这个虚拟第三方实际上是一套服务器,即使有一个恶意(但非含混)的对手,也无法单独学习任何东西。该领域以前的工作仅限于一个特定的启动功能:ReLU,使许多使用案例所使用的方法不切实际。第一次,我们为所有共同启动功能提供快速和可核查的协议,并优化它们以秘密共享的方式运行。快速、可核实和强有力地将快速、软式、软式、像样的服务器等功能拼凑在一起,让我们不用修改而使用先前的书写 NNPs,大大降低开发者的努力和代码的复杂性。最近,ReLU发现与非直线性化的推进功能相比,也更快速和可实现计算效率,比如说,我们把其直线性、不伸缩性、不伸缩性、不伸缩性、不伸缩式的功能伸缩。