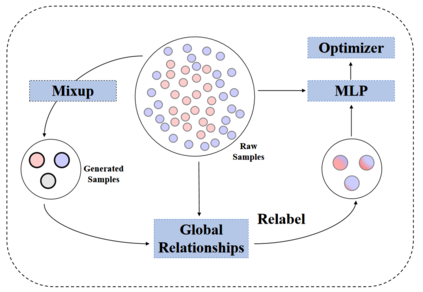
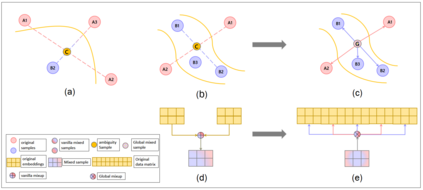
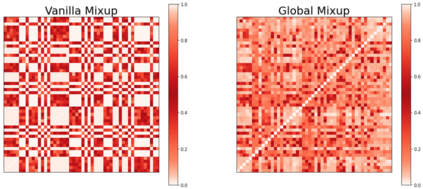
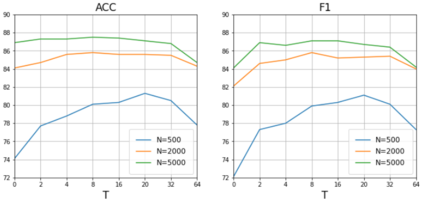
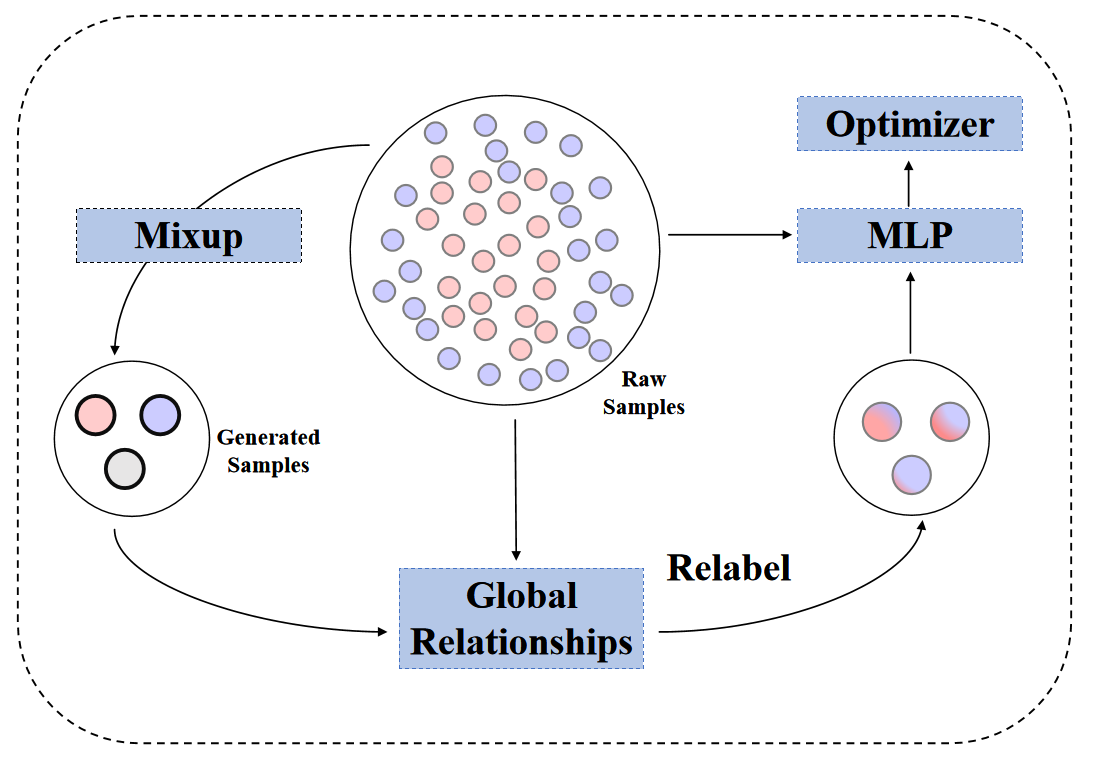
Data augmentation with \textbf{Mixup} has been proven an effective method to regularize the current deep neural networks. Mixup generates virtual samples and corresponding labels at once through linear interpolation. However, this one-stage generation paradigm and the use of linear interpolation have the following two defects: (1) The label of the generated sample is directly combined from the labels of the original sample pairs without reasonable judgment, which makes the labels likely to be ambiguous. (2) linear combination significantly limits the sampling space for generating samples. To tackle these problems, we propose a novel and effective augmentation method based on global clustering relationships named \textbf{Global Mixup}. Specifically, we transform the previous one-stage augmentation process into two-stage, decoupling the process of generating virtual samples from the labeling. And for the labels of the generated samples, relabeling is performed based on clustering by calculating the global relationships of the generated samples. In addition, we are no longer limited to linear relationships but generate more reliable virtual samples in a larger sampling space. Extensive experiments for \textbf{CNN}, \textbf{LSTM}, and \textbf{BERT} on five tasks show that Global Mixup significantly outperforms previous state-of-the-art baselines. Further experiments also demonstrate the advantage of Global Mixup in low-resource scenarios.
翻译:事实证明,通过\ textbf{ Mixup} 增强数据,是规范当前深神经网络的有效方法。混合通过线性内插,同时生成虚拟样本和相应的标签。然而,这种一阶段生成模式和线性内插法的使用有以下两个缺陷:(1) 生成样本的标签直接来自原始样本配对的标签,而没有合理的判断,这使得标签有可能是模糊的。 (2) 线性组合极大地限制了生成样本的取样空间。为了解决这些问题,我们提议了一种新型和有效的增强方法,其基础是名为\ textbf{ Global mix}的全球集群关系。具体地说,我们把先前的一阶段增强进程转换为两阶段,将生成虚拟样本的过程与标签脱钩。对于生成样本的标签,则通过计算生成样本的全球关系,进行重新标签。此外,我们不再局限于线性关系,而是在更大的取样空间中生成更可靠的虚拟样本。 广泛实验用于\ CNNfff{ Glob} MLIS 的低层实验, 也展示了之前的MFlexx 。