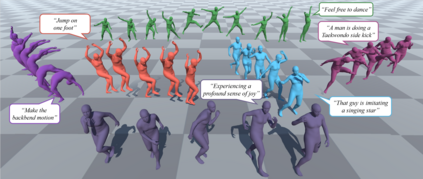
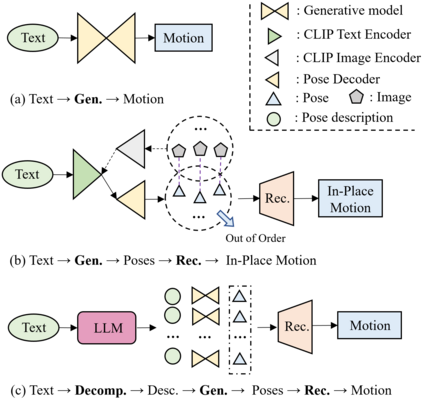
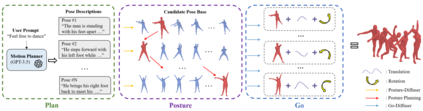
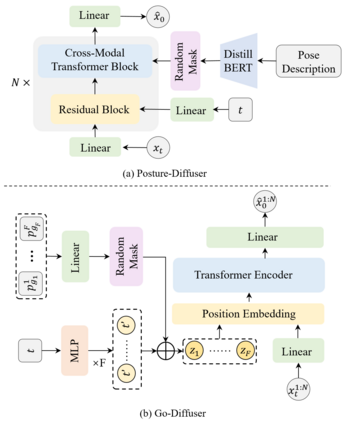
Conventional text-to-motion generation methods are usually trained on limited text-motion pairs, making them hard to generalize to open-world scenarios. Some works use the CLIP model to align the motion space and the text space, aiming to enable motion generation from natural language motion descriptions. However, they are still constrained to generate limited and unrealistic in-place motions. To address these issues, we present a divide-and-conquer framework named PRO-Motion, which consists of three modules as motion planner, posture-diffuser and go-diffuser. The motion planner instructs Large Language Models (LLMs) to generate a sequence of scripts describing the key postures in the target motion. Differing from natural languages, the scripts can describe all possible postures following very simple text templates. This significantly reduces the complexity of posture-diffuser, which transforms a script to a posture, paving the way for open-world generation. Finally, go-diffuser, implemented as another diffusion model, estimates whole-body translations and rotations for all postures, resulting in realistic motions. Experimental results have shown the superiority of our method with other counterparts, and demonstrated its capability of generating diverse and realistic motions from complex open-world prompts such as "Experiencing a profound sense of joy". The project page is available at https://moonsliu.github.io/Pro-Motion.
翻译:暂无翻译