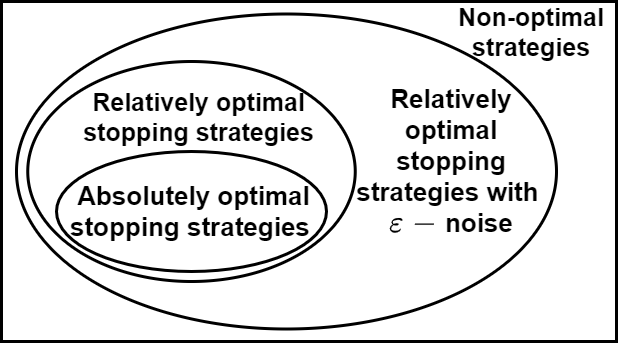
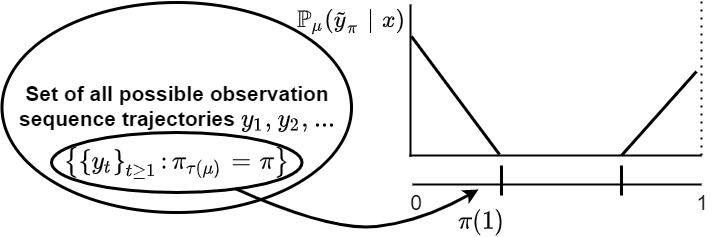
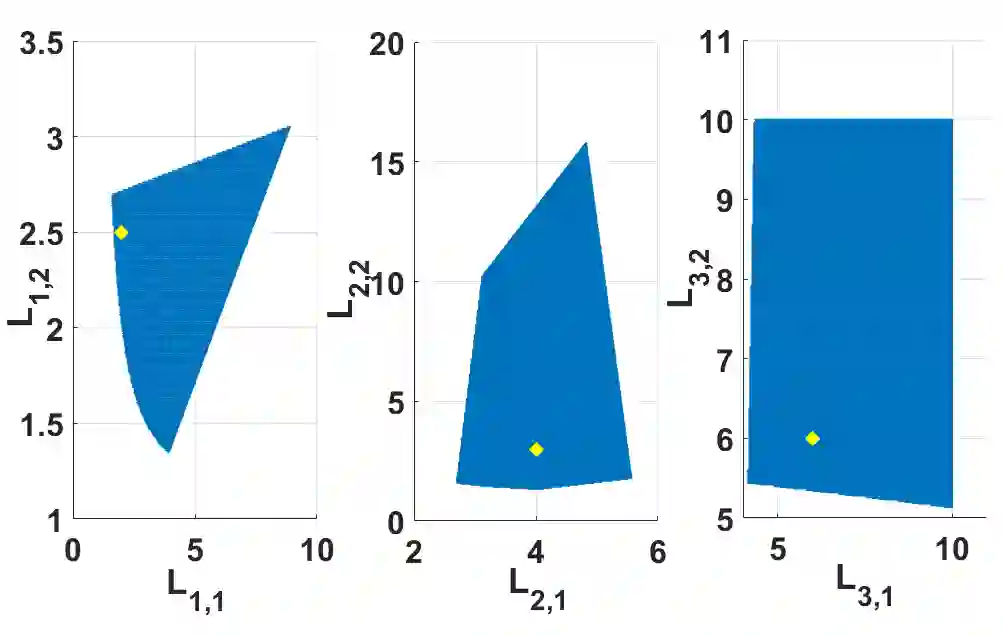
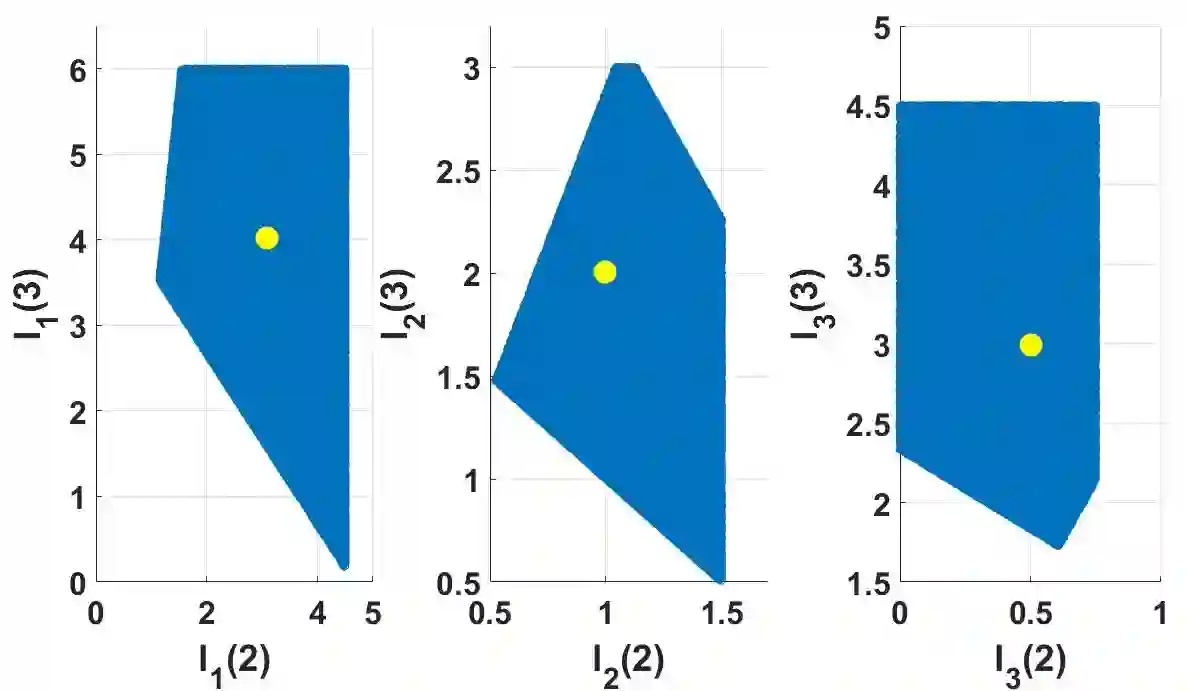
This paper presents an inverse reinforcement learning (IRL) framework for Bayesian stopping time problems. By observing the actions of a Bayesian decision maker, we provide a necessary and sufficient condition to identify if these actions are consistent with optimizing a cost function; then we construct set valued estimates of the cost function. To achieve this IRL objective, we use novel ideas from Bayesian revealed preferences stemming from microeconomics. To illustrate our IRL scheme,we consider two important examples of stopping time problems, namely, sequential hypothesis testing and Bayesian search. Finally, for finite datasets, we propose an IRL detection algorithm and give finite sample bounds on its error probabilities. Also we discuss how to identify $\epsilon$-optimal Bayesian decision makers and perform IRL.
翻译:本文为巴伊西亚停止时间问题提供了一个反向强化学习框架。 通过观察巴伊西亚决策者的行动, 我们为确定这些行动是否符合优化成本功能提供了必要和充分的条件; 然后我们构建了成本功能的定值估计值。 为了实现IRL的目标, 我们使用来自巴伊西亚人透露的来自微观经济学的偏好的新想法。 为了说明我们的IRL计划, 我们考虑了两个阻止时间问题的重要例子, 即连续的假设测试和Bayesian搜索。 最后, 对于有限的数据集, 我们提出IRL检测算法, 并给出其错误概率的有限样本界限 。 我们还讨论如何确定$\ epsilon- optimal Bayesian决策者并进行 IRL 。