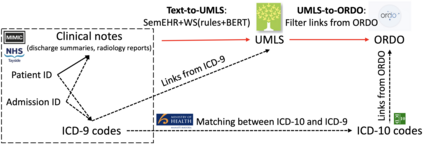
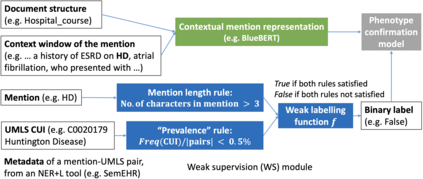
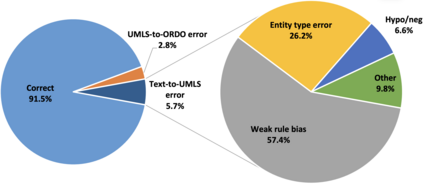
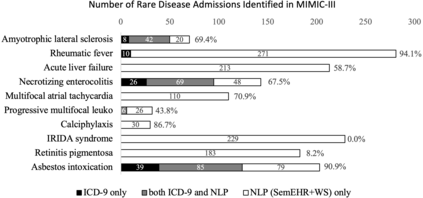
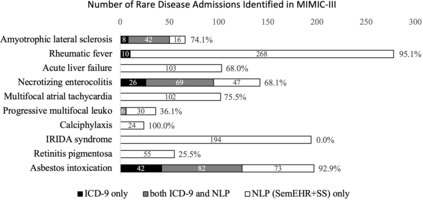
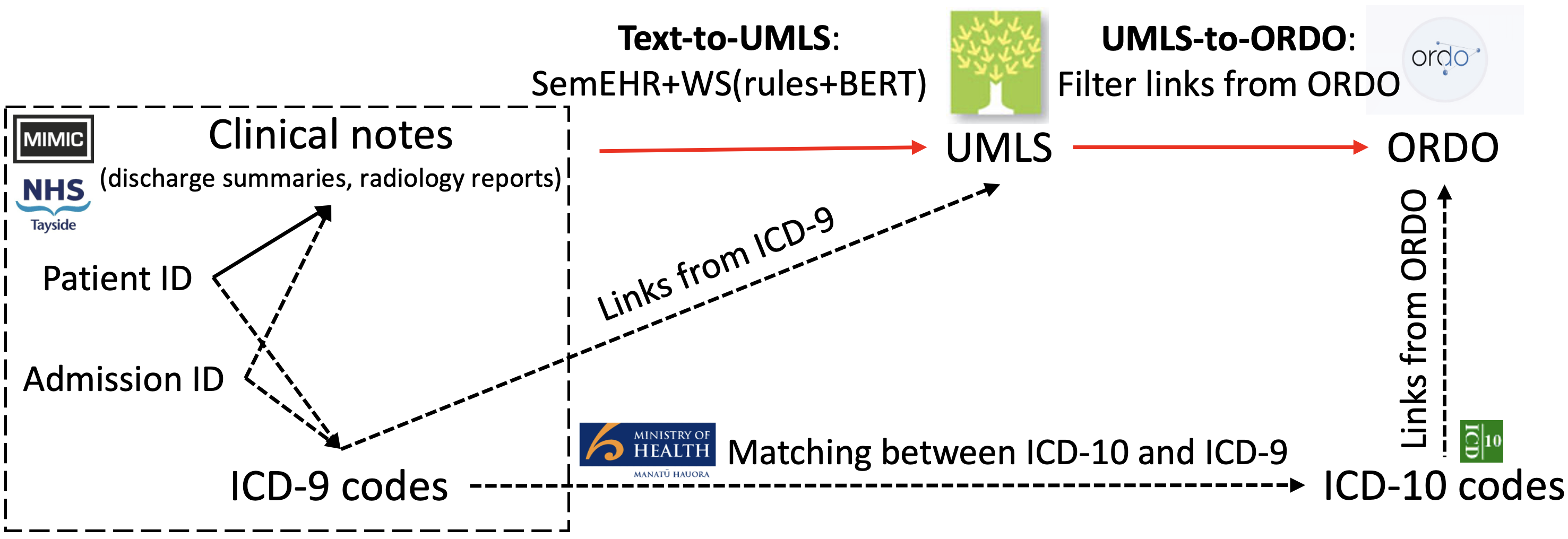
Computational text phenotyping is the practice of identifying patients with certain disorders and traits from clinical notes. Rare diseases are challenging to be identified due to few cases available for machine learning and the need for data annotation from domain experts. We propose a method using ontologies and weak supervision, with recent pre-trained contextual representations from Bi-directional Transformers (e.g. BERT). The ontology-based framework includes two steps: (i) Text-to-UMLS, extracting phenotypes by contextually linking mentions to concepts in Unified Medical Language System (UMLS), with a Named Entity Recognition and Linking (NER+L) tool, SemEHR, and weak supervision with customised rules and contextual mention representation; (ii) UMLS-to-ORDO, matching UMLS concepts to rare diseases in Orphanet Rare Disease Ontology (ORDO). The weakly supervised approach is proposed to learn a phenotype confirmation model to improve Text-to-UMLS linking, without annotated data from domain experts. We evaluated the approach on three clinical datasets, MIMIC-III discharge summaries, MIMIC-III radiology reports, and NHS Tayside brain imaging reports from two institutions in the US and the UK, with annotations. Our best weakly supervised method achieved 81.4% precision and 91.4% recall on extracting rare disease UMLS phenotypes from the annotated MIMIC-III discharge summaries. Results on radiology reports from MIMIC-III and NHS Tayside were consistent with the discharge summaries. The overall pipeline processing clinical notes can extract rare disease cases, mostly uncaptured in structured data (manually assigned ICD codes). We discuss the usefulness of the weak supervision approach and propose directions for future studies.
翻译:计算文本内容是确定某些障碍患者和临床笔记的特征。由于机器学习的病例很少,而且需要来自域专家的数据注释,因此发现罕见的疾病具有挑战性。我们提出一种使用肿瘤和薄弱监督的方法,最近通过双向变换器(如BERT)对背景进行预先培训,由两向变换器(如:BERT)对 UMLS进行背景介绍。基于肿瘤的框架包括两个步骤:(一) 文本到UMLS,通过从背景角度将提及与统一医疗语言系统(UMCDLS)中的概念联系起来来提取线性类型。由于机器学习的病例很少,因此难以识别和链接(NER+L)工具,SemEHR,以及定制规则和背景标签代表的监管薄弱;(二) UMLS到ORDO,将UMLS概念与罕见疾病(ORDO) IMLS 进行预先培训。我们建议采用一种稀有型的确认模式来改进文本到UMLS的链接和UMLS的链接,而没有由域专家提供附加的数据。我们在三个临床分流流处理的三总目录流流流流流流报告中,IMIII MIMIMIMIIII 和IMAS最弱的IMIS报告中,在两个分解的准确的IMIS报告中提出一种最精确的解的 RIS结果。