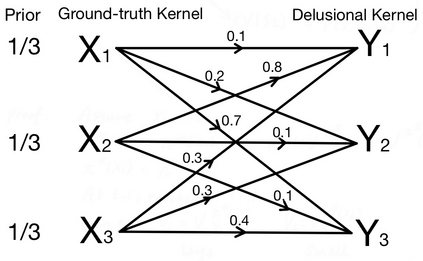
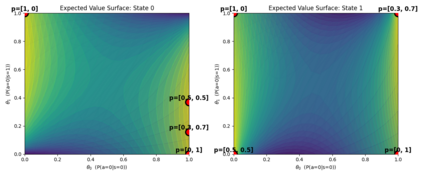
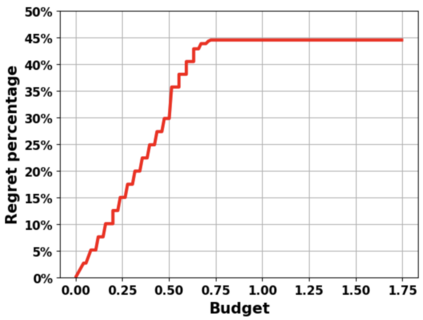
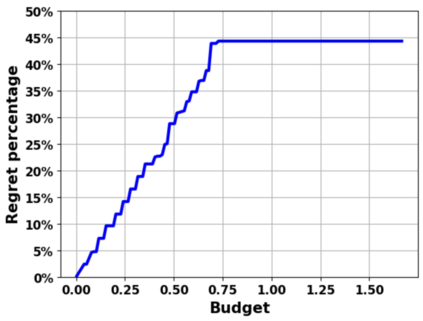
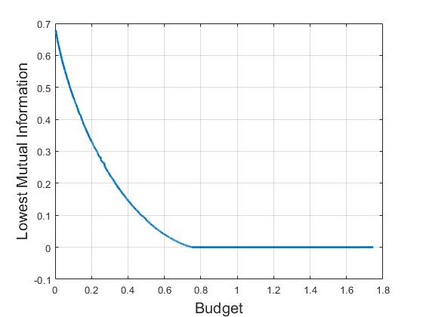
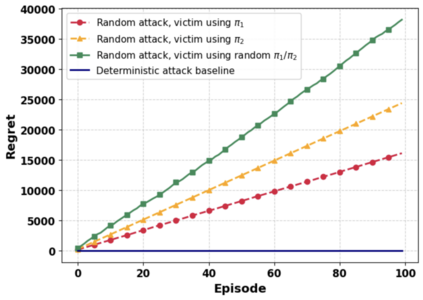
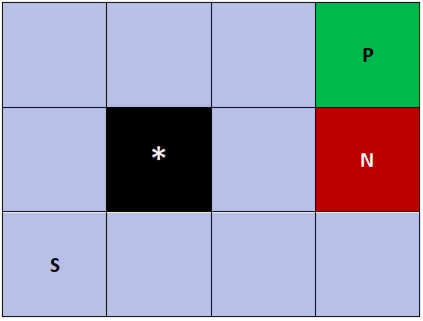
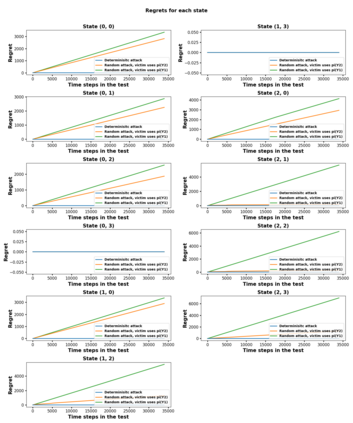
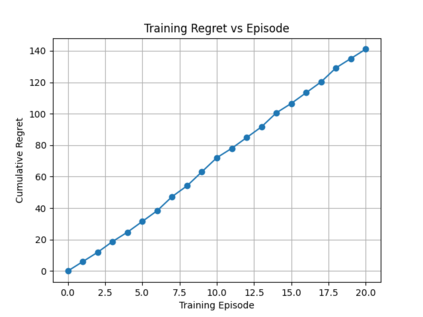
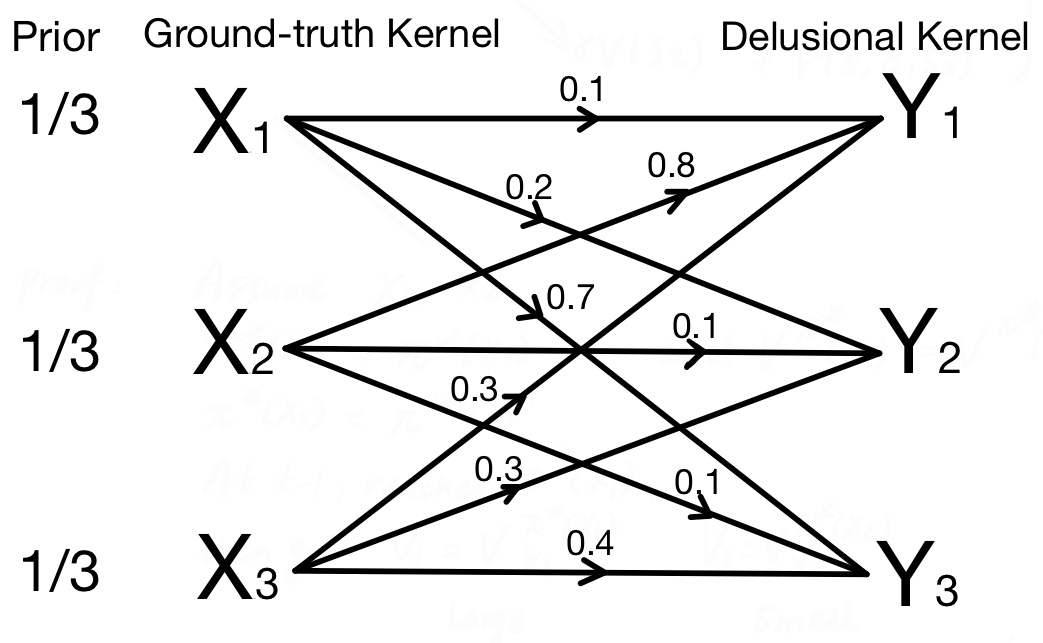
Reinforcement learning (RL) for the Markov Decision Process (MDP) has emerged in many security-related applications, such as autonomous driving, financial decisions, and drone/robot algorithms. In order to improve the robustness/defense of RL systems against adversaries, studying various adversarial attacks on RL systems is very important. Most previous work considered deterministic adversarial attack strategies in MDP, which the recipient (victim) agent can defeat by reversing the deterministic attacks. In this paper, we propose a provably ``invincible'' or ``uncounterable'' type of adversarial attack on RL. The attackers apply a rate-distortion information-theoretic approach to randomly change agents' observations of the transition kernel (or other properties) so that the agent gains zero or very limited information about the ground-truth kernel (or other properties) during the training. We derive an information-theoretic lower bound on the recipient agent's reward regret and show the impact of rate-distortion attacks on state-of-the-art model-based and model-free algorithms. We also extend this notion of an information-theoretic approach to other types of adversarial attack, such as state observation attacks.
翻译:暂无翻译