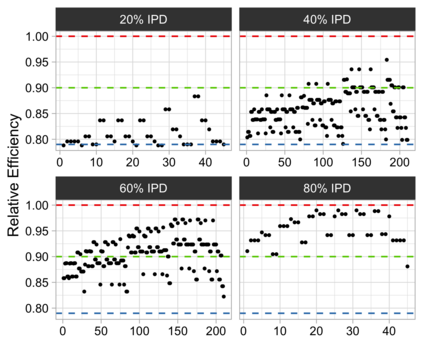
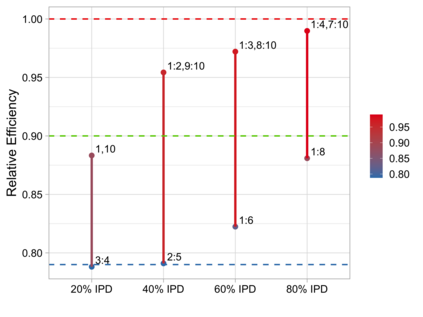
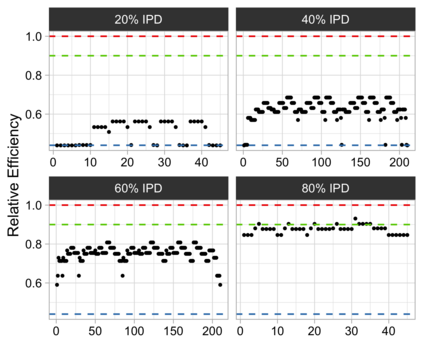
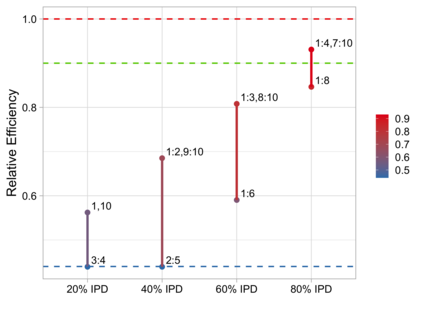
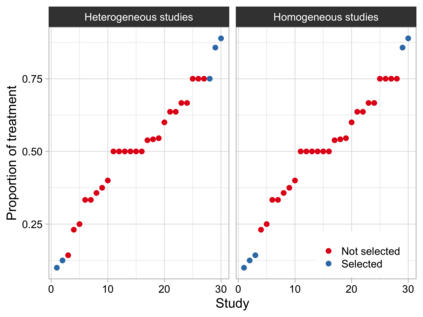
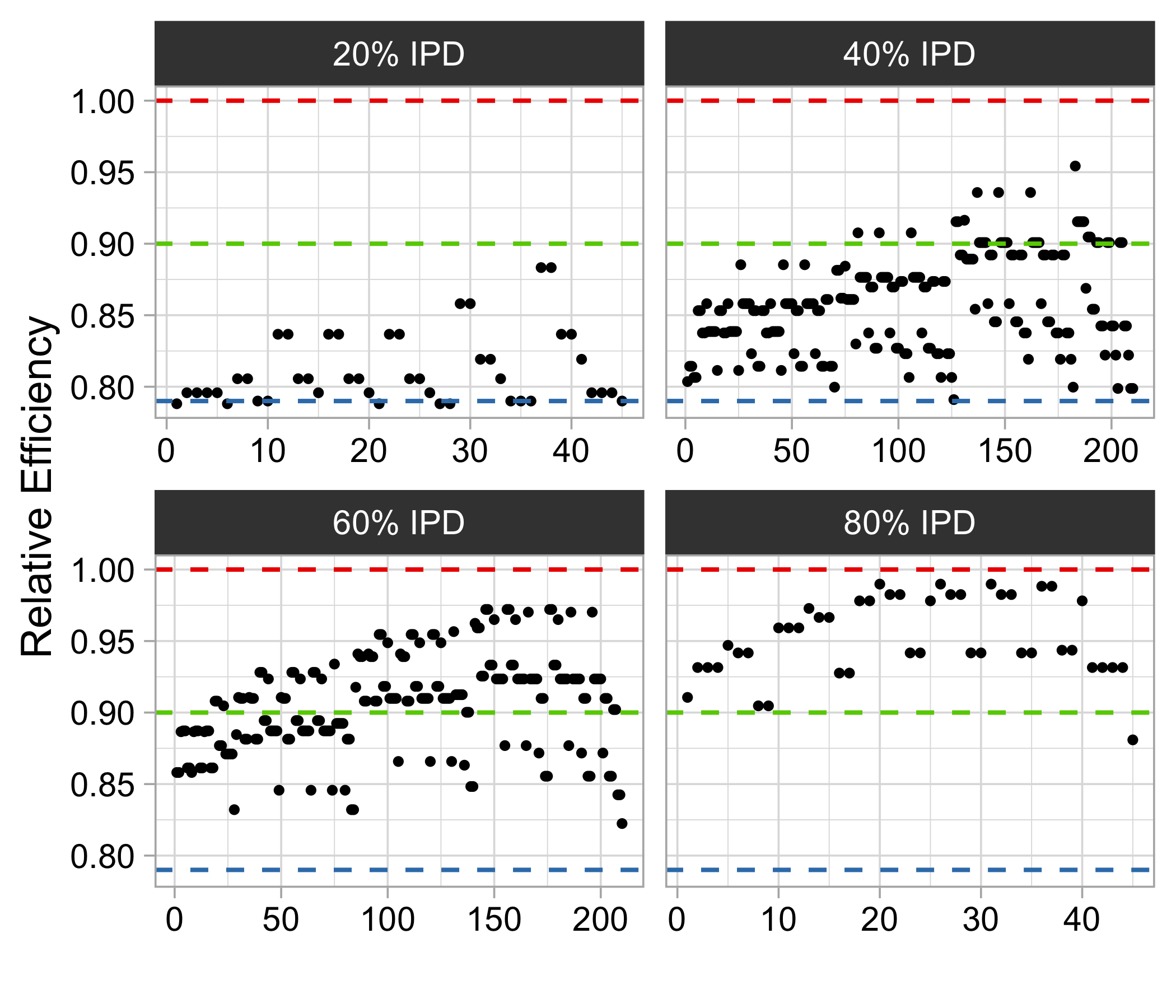
Often both Aggregate Data (AD) studies and Individual Patient Data (IPD) studies are available for specific treatments. Combining these two sources of data could improve the overall meta-analytic estimates of treatment effects. Moreover, often for some studies with AD, the associated IPD maybe available, albeit at some extra effort or cost to the analyst. We propose a method for combining treatment effects across trials when the response is from the exponential family of distribution and hence a generalized linear model structure can be used. We consider the case when treatment effects are fixed and common across studies. Using the proposed combination method, we evaluate the wisdom of choosing AD when IPD is available by studying the relative efficiency of analyzing all IPD studies versus combining various percentages of AD and IPD studies. For many different models design constraints under which the AD estimators are the IPD estimators, and hence fully efficient, are known. For such models we advocate a selection procedure that chooses AD studies over IPD studies in a manner that force least departure from design constraints and hence ensures a fully efficient combined AD and IPD estimator.
翻译:通常,综合数据(AD)研究和个别病人数据(IPD)研究都可用于具体治疗。这两个数据来源相结合,可以改善对治疗效果的总体元分析估计。此外,对于一些与AD有关的研究,相关的IPD也许可以使用,尽管有些额外努力或分析师的费用。我们建议一种方法,在反应来自指数分布式分布式分布式分布式分布式分布式分布式分布式分布式分布式分布式分布式分布式,因而可以使用一个通用的线性模型结构时,将所有治疗效果固定和常见时的情况结合起来。我们采用拟议的组合方法,通过研究分析所有IDD研究的相对效率,同时结合AD和IDD和IDD研究的多种百分比,来评估在具备IPD时选择A的明智性。对于许多不同的模型设计限制,即AD估计者是IPD估计者,因此是完全有效的。对于这些模型,我们提倡一种选择程序,选择AD研究而不是IDD研究,其方式应尽量避免脱离设计上的制约,从而确保充分有效的ADD和IDD综合估计。