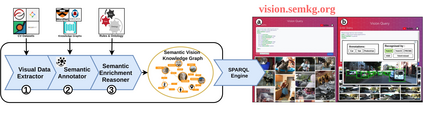
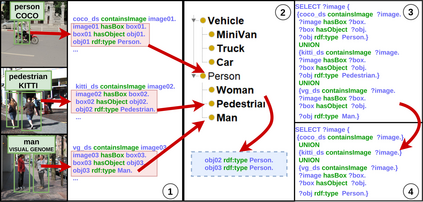
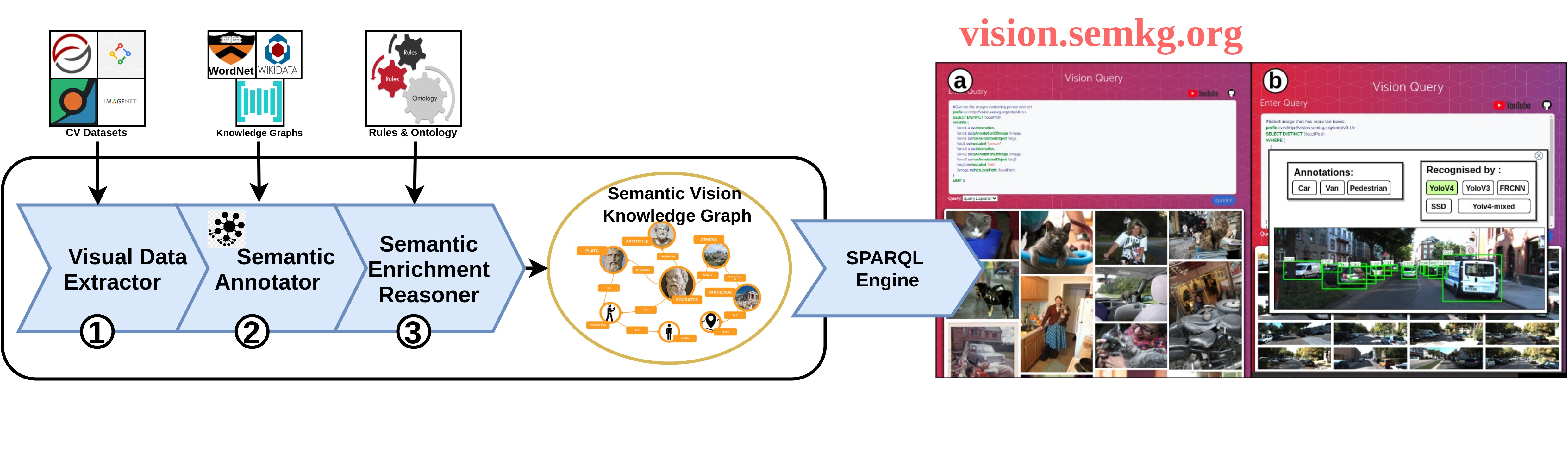
It is commonly acknowledged that the availability of the huge amount of (training) data is one of the most important factors for many recent advances in Artificial Intelligence (AI). However, datasets are often designed for specific tasks in narrow AI sub areas and there is no unified way to manage and access them. This not only creates unnecessary overheads when training or deploying Machine Learning models but also limits the understanding of the data, which is very important for data-centric AI. In this paper, we present our vision about a unified framework for different datasets so that they can be integrated and queried easily, e.g., using standard query languages. We demonstrate this in our ongoing work to create a framework for datasets in Computer Vision and show its advantages in different scenarios. Our demonstration is available at https://vision.semkg.org.
翻译:人们普遍承认,大量(培训)数据的可得性是人造情报(AI)最近取得许多进展的最重要因素之一,然而,数据集往往是为狭隘的AI子领域的具体任务设计的,没有统一的管理和获取方法,这不仅在培训或部署机器学习模型时造成不必要的间接费用,而且限制了对数据的理解,这对以数据为中心的AI非常重要。在本文件中,我们提出了关于不同数据集统一框架的愿景,以便它们能够容易地整合和查询,例如,使用标准查询语言。我们在为计算机视野数据集创建框架并显示其在不同情况下的优势的现行工作中证明了这一点。我们的示范可在https://vision.semkg.org上查阅。