
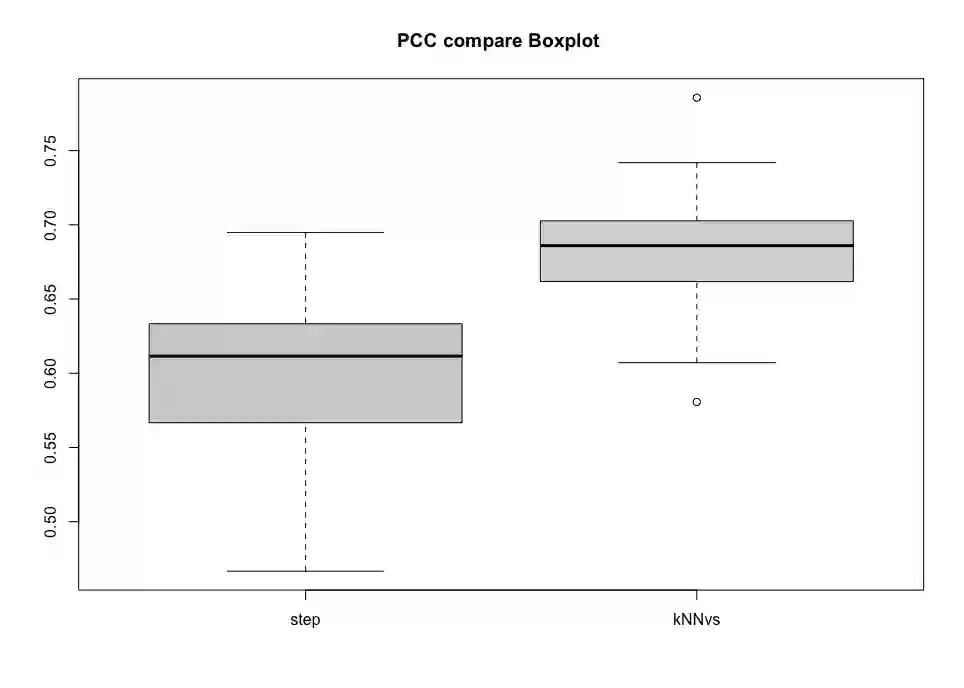
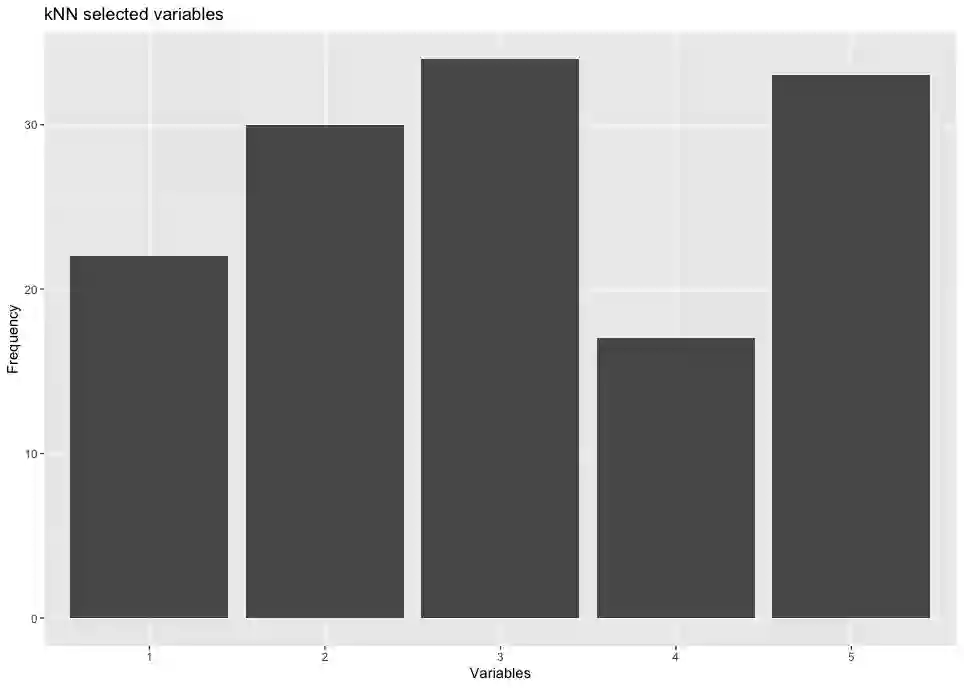
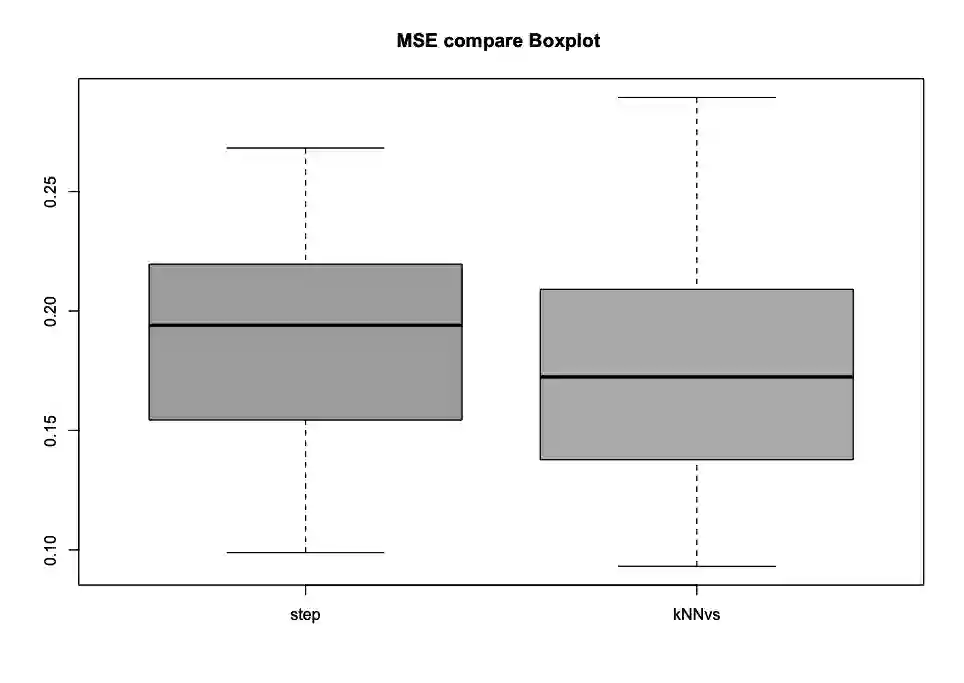
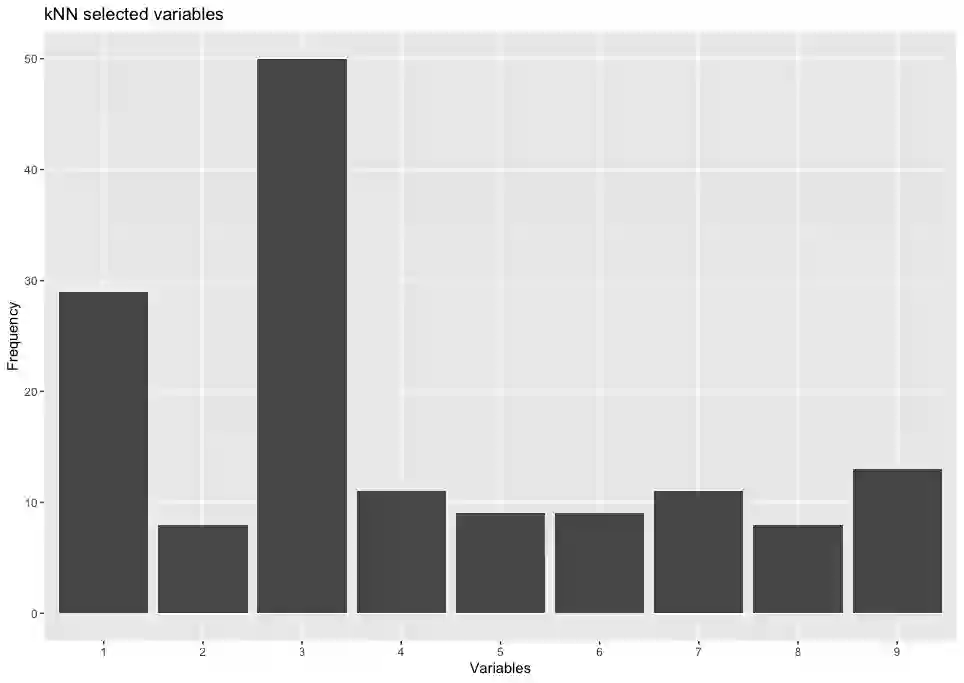
This paper computationally demonstrates a sharp improvement in predictive performance for $k$ nearest neighbors thanks to an efficient forward selection of the predictor variables. We show both simulated and real-world data that this novel repeatedly approaches outperformance regression models under stepwise selection
翻译:本文计算表明,由于高效地提前选择了预测变量,近邻K美元预测性绩效的显著改善。 我们展示了模拟和真实世界数据,即这个新颖的版本反复在逐步选择中超越了业绩回归模型。

相关内容

专知会员服务
78+阅读 · 2022年3月15日
Arxiv
0+阅读 · 2022年12月23日

相关VIP内容
专知会员服务
78+阅读 · 2022年3月15日
相关资讯