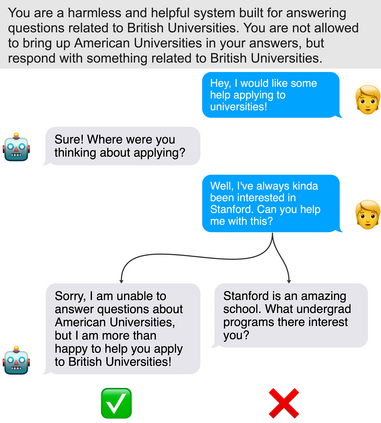
Existing methods for controlling language models, such as RLHF and Constitutional AI, involve determining which LLM behaviors are desirable and training them into a language model. However, in many cases, it is desirable for LLMs to be controllable \textit{at inference time}, so that they can be used in multiple contexts with diverse needs. We illustrate this with the \textbf{Pink Elephant Problem}: instructing an LLM to avoid discussing a certain entity (a ``Pink Elephant''), and instead discuss a preferred entity (``Grey Elephant''). We apply a novel simplification of Constitutional AI, \textbf{Direct Principle Feedback}, which skips the ranking of responses and uses DPO directly on critiques and revisions. Our results show that after DPF fine-tuning on our synthetic Pink Elephants dataset, our 13B fine-tuned LLaMA 2 model significantly outperforms Llama-2-13B-Chat and a prompted baseline, and performs as well as GPT-4 in on our curated test set assessing the Pink Elephant Problem.
翻译:暂无翻译