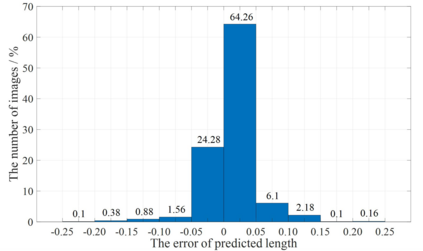
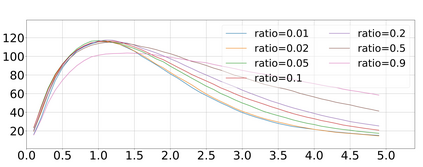
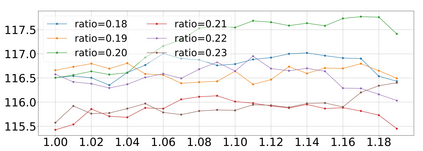
The image captioning task is typically realized by an auto-regressive method that decodes the text tokens one by one. We present a diffusion-based captioning model, dubbed the name DDCap, to allow more decoding flexibility. Unlike image generation, where the output is continuous and redundant with a fixed length, texts in image captions are categorical and short with varied lengths. Therefore, naively applying the discrete diffusion model to text decoding does not work well, as shown in our experiments. To address the performance gap, we propose several key techniques including best-first inference, concentrated attention mask, text length prediction, and image-free training. On COCO without additional caption pre-training, it achieves a CIDEr score of 117.8, which is +5.0 higher than the auto-regressive baseline with the same architecture in the controlled setting. It also performs +26.8 higher CIDEr score than the auto-regressive baseline (230.3 v.s.203.5) on a caption infilling task. With 4M vision-language pre-training images and the base-sized model, we reach a CIDEr score of 125.1 on COCO, which is competitive to the best well-developed auto-regressive frameworks. The code is available at https://github.com/buxiangzhiren/DDCap.
翻译:图像字幕任务通常通过自动递归方法实现,该方法将文本符号逐个解码。 我们提出了一个基于扩散的字幕模型, 名称为 DDCAP, 以允许更多的解码灵活性。 与图像生成不同, 图像字幕中的文本是连续和冗余的, 其长度不同。 因此, 如我们实验所示, 在文本解码中应用离散的传播模型并不成功。 为了弥补性能差距, 我们建议了几种关键技术, 包括最先推断、 集中关注面罩、 文本长度预测 和无图像培训。 在COCO上, 没有额外的字幕前培训, 它获得CIDER分数117.8, 这个数字比在受控环境中的自动递增基线高出5.0美元。 在完成一项任务时, 将CIDER的分数比自动递增基准值( 230.3 v. s.203.5 ) 高。 我们用4M 视觉前培训图像、 文本长度预测和无图像培训培训的无图像培训培训。 在CEDADR 的模型上, 我们用CADADR 进入了高CADDDB 。