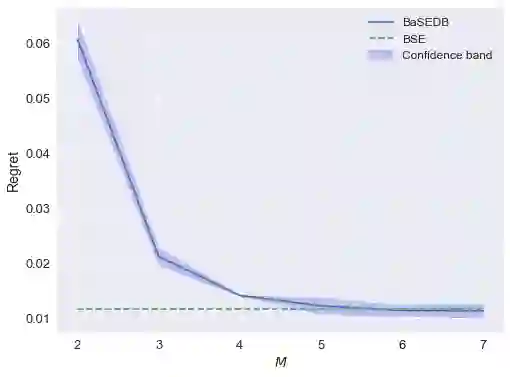
We study nonparametric contextual bandits under batch constraints, where the expected reward for each action is modeled as a smooth function of covariates, and the policy updates are made at the end of each batch of observations. We establish a minimax regret lower bound for this setting and propose Batched Successive Elimination with Dynamic Binning (BaSEDB) that achieves optimal regret (up to logarithmic factors). In essence, BaSEDB dynamically splits the covariate space into smaller bins, carefully aligning their widths with the batch size. We also show the suboptimality of static binning under batch constraints, highlighting the necessity of dynamic binning. Additionally, our results suggest that a nearly constant number of policy updates can attain optimal regret in the fully online setting.
翻译:暂无翻译