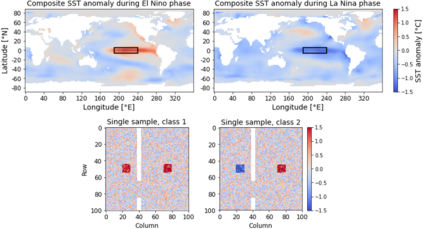
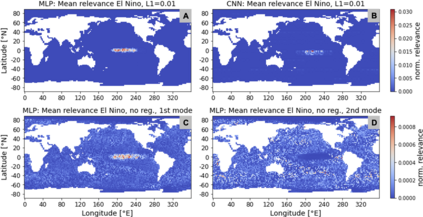
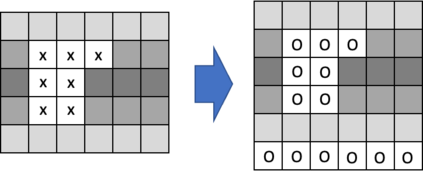
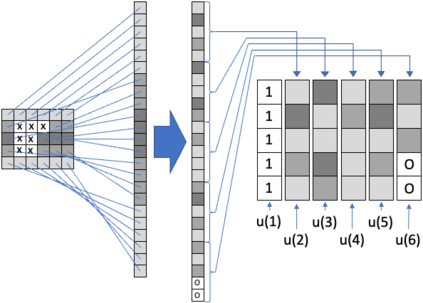
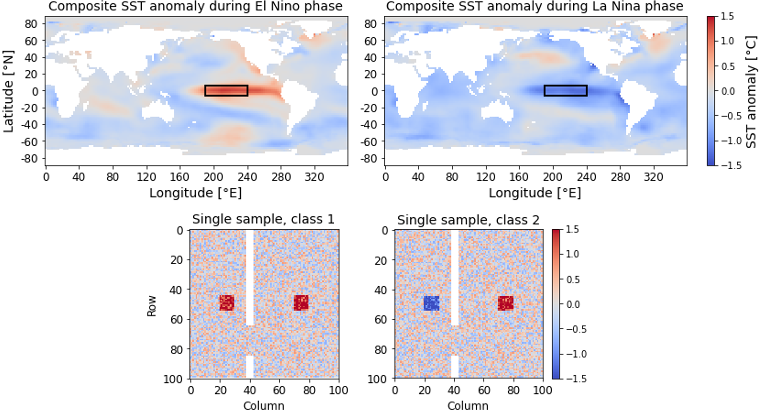
Layer-wise relevance propagation (LRP) is a widely used and powerful technique to reveal insights into various artificial neural network (ANN) architectures. LRP is often used in the context of image classification. The aim is to understand, which parts of the input sample have highest relevance and hence most influence on the model prediction. Relevance can be traced back through the network to attribute a certain score to each input pixel. Relevance scores are then combined and displayed as heat maps and give humans an intuitive visual understanding of classification models. Opening the black box to understand the classification engine in great detail is essential for domain experts to gain trust in ANN models. However, there are pitfalls in terms of model-inherent artifacts included in the obtained relevance maps, that can easily be missed. But for a valid interpretation, these artifacts must not be ignored. Here, we apply and revise LRP on various ANN architectures trained as classifiers on geospatial and synthetic data. Depending on the network architecture, we show techniques to control model focus and give guidance to improve the quality of obtained relevance maps to separate facts from artifacts.
翻译:暂无翻译