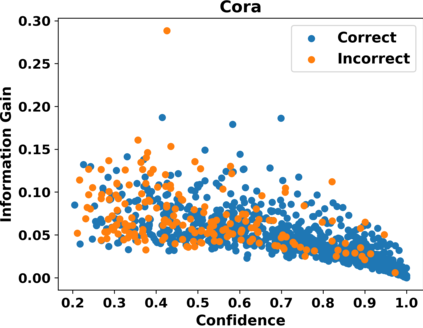
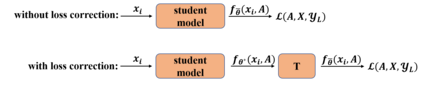
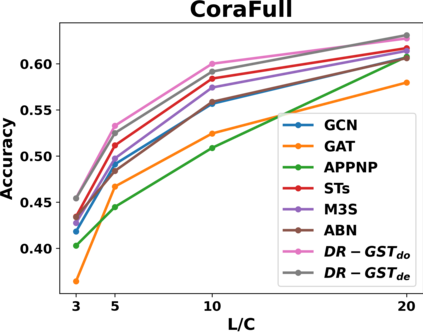
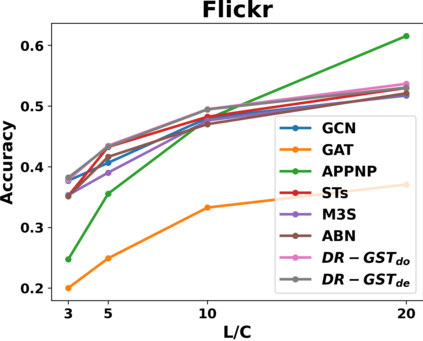
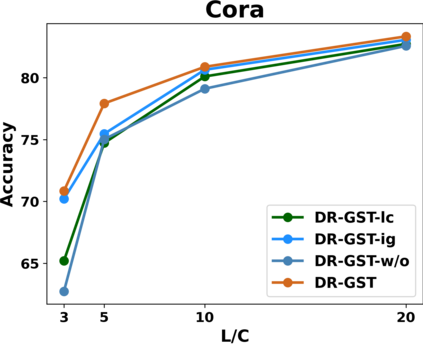
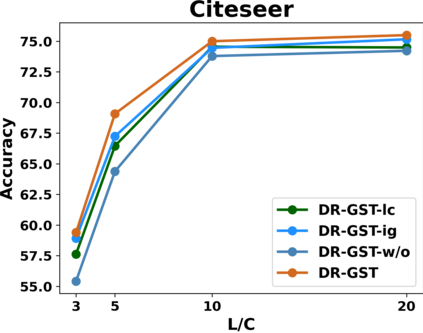
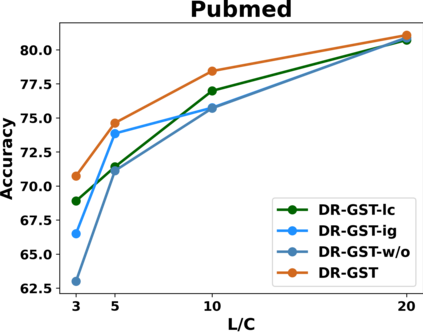
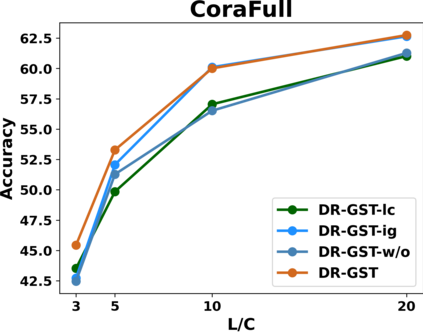
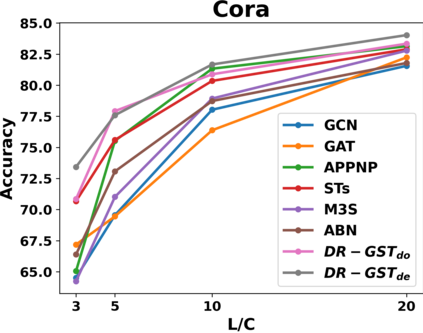
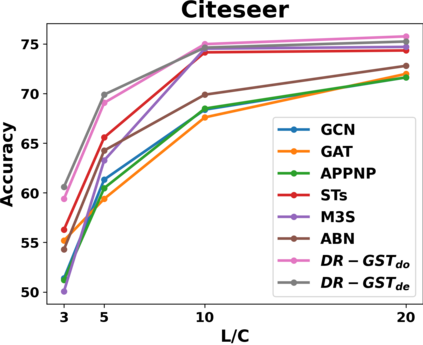
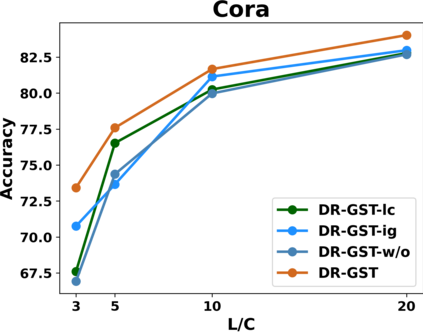
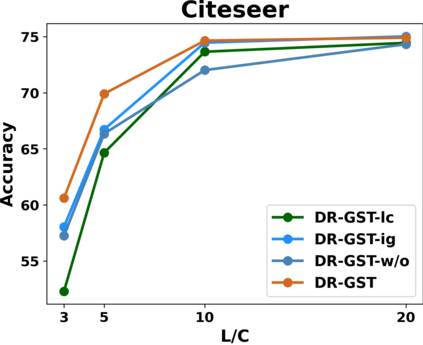
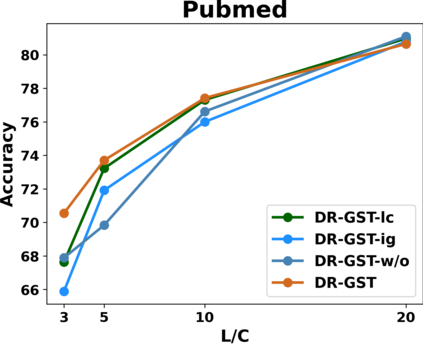
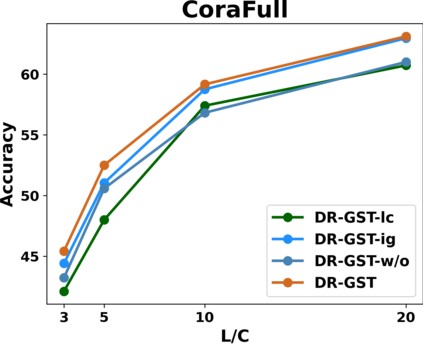
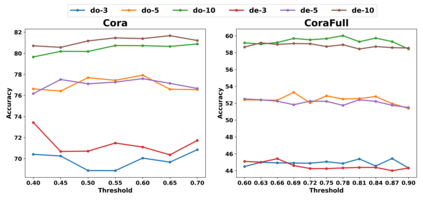
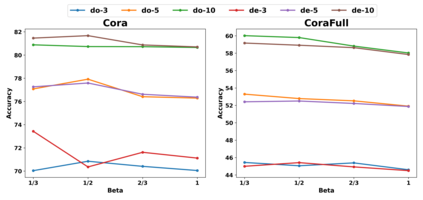
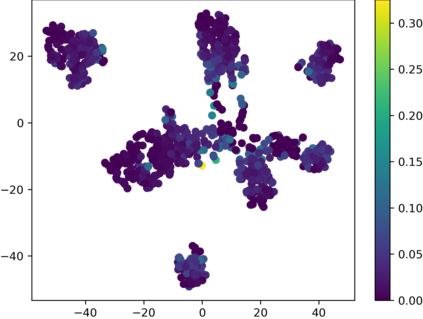
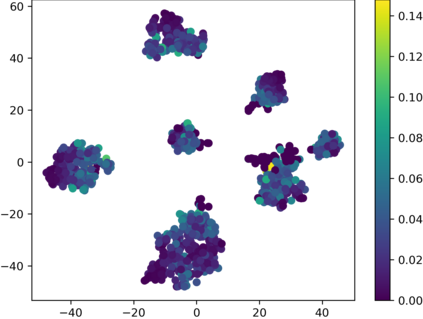
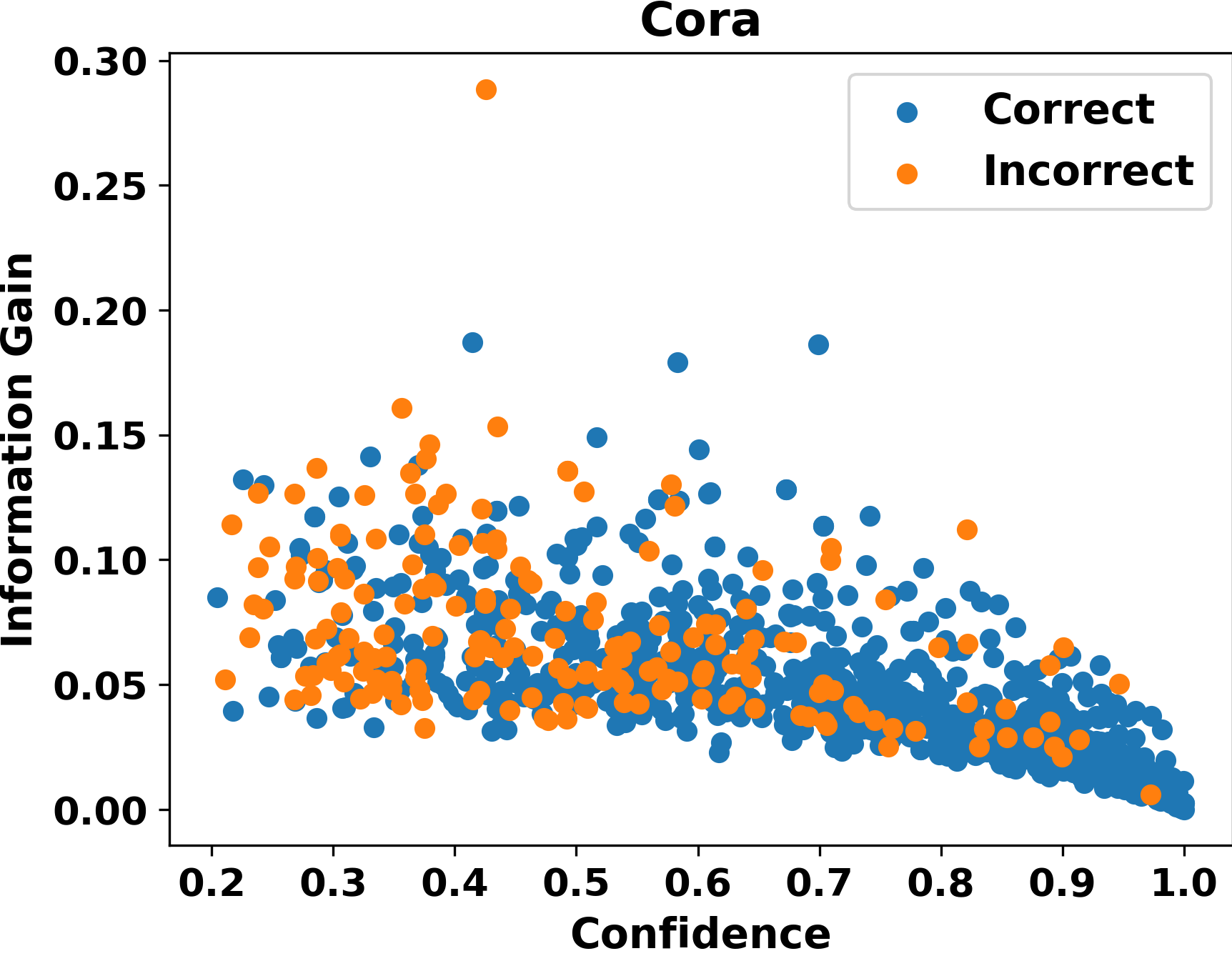
Graph Convolutional Networks (GCNs) have recently attracted vast interest and achieved state-of-the-art performance on graphs, but its success could typically hinge on careful training with amounts of expensive and time-consuming labeled data. To alleviate labeled data scarcity, self-training methods have been widely adopted on graphs by labeling high-confidence unlabeled nodes and then adding them to the training step. In this line, we empirically make a thorough study for current self-training methods on graphs. Surprisingly, we find that high-confidence unlabeled nodes are not always useful, and even introduce the distribution shift issue between the original labeled dataset and the augmented dataset by self-training, severely hindering the capability of self-training on graphs. To this end, in this paper, we propose a novel Distribution Recovered Graph Self-Training framework (DR-GST), which could recover the distribution of the original labeled dataset. Specifically, we first prove the equality of loss function in self-training framework under the distribution shift case and the population distribution if each pseudo-labeled node is weighted by a proper coefficient. Considering the intractability of the coefficient, we then propose to replace the coefficient with the information gain after observing the same changing trend between them, where information gain is respectively estimated via both dropout variational inference and dropedge variational inference in DR-GST. However, such a weighted loss function will enlarge the impact of incorrect pseudo labels. As a result, we apply the loss correction method to improve the quality of pseudo labels. Both our theoretical analysis and extensive experiments on five benchmark datasets demonstrate the effectiveness of the proposed DR-GST, as well as each well-designed component in DR-GST.
翻译:革命网络(GCN)最近吸引了巨大的兴趣,并实现了图表上最先进的节点,但成功与否通常取决于使用大量昂贵和耗时的标签数据进行仔细培训。为了减轻标签数据稀缺性,在图表上广泛采用了自我培训方法,贴上高自信无标签节点标签,然后将其添加到培训步骤。在这条线上,我们实证地对当前图表上的自培训方法进行了彻底研究。令人惊讶的是,我们发现高信心无标签的节点并不总是有用,甚至可能引入原始标签数据集与自我培训增加的数据集之间的分配变化问题。为了减轻标签数据稀缺的数据稀缺,自培训方法在图表上被广泛广泛采用。为此,我们提议了一个新的发行回收的图表自修框架(DR-GST),这个框架可以恢复原有标签数据集的分布。我们首先证明,在分布变换的自我培训框架下,在每次贴标签的质量数据集中,在质量和人口分布分配中,如果每个不准确的自译的自译的自译的自译节节点都会在自我分析中,在不断变。