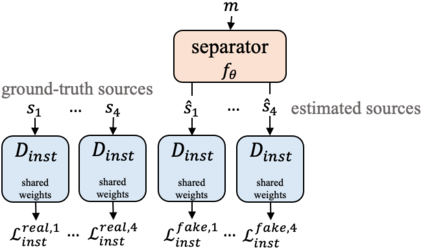
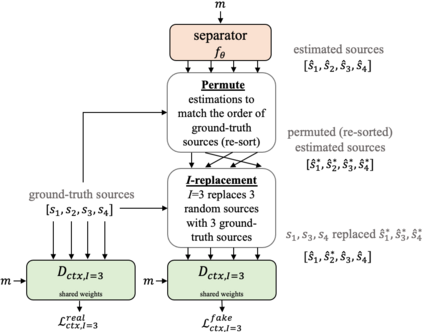
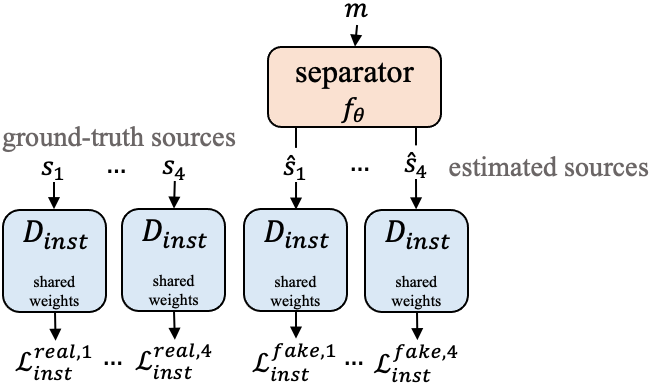
Universal sound separation consists of separating mixes with arbitrary sounds of different types, and permutation invariant training (PIT) is used to train source agnostic models that do so. In this work, we complement PIT with adversarial losses but find it challenging with the standard formulation used in speech source separation. We overcome this challenge with a novel I-replacement context-based adversarial loss, and by training with multiple discriminators. Our experiments show that by simply improving the loss (keeping the same model and dataset) we obtain a non-negligible improvement of 1.4 dB SI-SNRi in the reverberant FUSS dataset. We also find adversarial PIT to be effective at reducing spectral holes, ubiquitous in mask-based separation models, which highlights the potential relevance of adversarial losses for source separation.
翻译:通用声音分离包括将混合物与不同类型任意声音分开,并使用变异性培训来培训这种类型的源的不可知模型。在这项工作中,我们用对抗性损失来补充PIT,但发现它因语言源分离中所使用的标准配方而具有挑战性。我们用一种新颖的I取代基于背景的对抗性损失和对多重歧视者的培训来克服这一挑战。我们的实验表明,通过简单地改进损失(保持相同的模型和数据集),我们在可变FUSS数据集中取得了1.4 dB SI-SNRI的不可忽略的改进。 我们还发现,对抗性PIT在减少光谱洞方面是有效的,在基于面具的分离模型中普遍存在,这凸显了对抗性损失对源分离的潜在相关性。