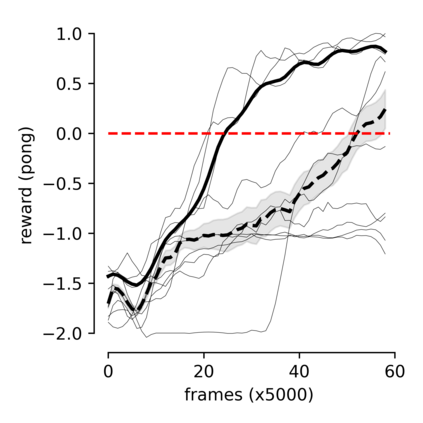
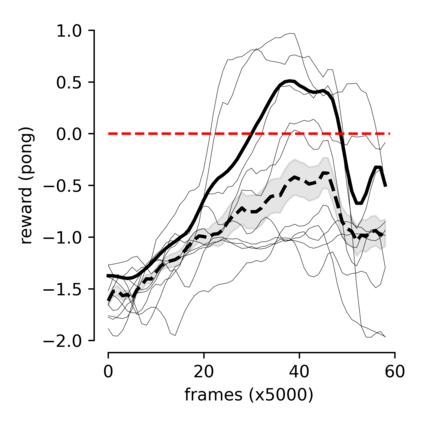
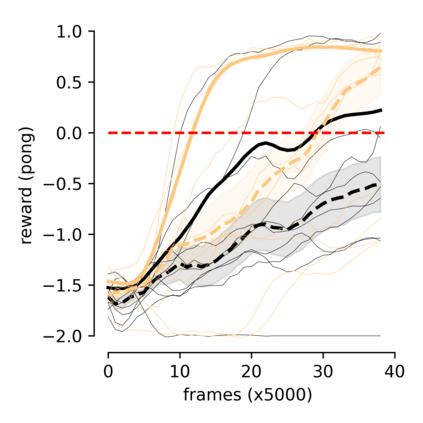
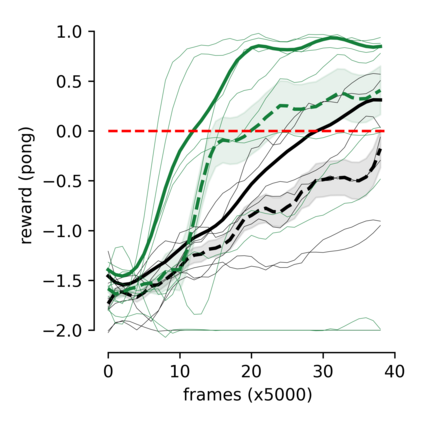
Humans and animals can learn new skills after practicing for a few hours, while current reinforcement learning algorithms require a large amount of data to achieve good performances. Recent model-based approaches show promising results by reducing the number of necessary interactions with the environment to learn a desirable policy. However, these methods require biological implausible ingredients, such as the detailed storage of older experiences, and long periods of offline learning. The optimal way to learn and exploit word-models is still an open question. Taking inspiration from biology, we suggest that dreaming might be an efficient expedient to use an inner model. We propose a two-module (agent and model) spiking neural network in which "dreaming" (living new experiences in a model-based simulated environment) significantly boosts learning. We also explore "planning", an online alternative to dreaming, that shows comparable performances. Importantly, our model does not require the detailed storage of experiences, and learns online the world-model and the policy. Moreover, we stress that our network is composed of spiking neurons, further increasing the biological plausibility and implementability in neuromorphic hardware.
翻译:人类和动物在练习数小时后可以学习新技能,而目前的强化学习算法需要大量数据才能取得良好的表现。最近的模型方法通过减少与环境的必要互动以学习理想的政策,显示了有希望的成果。然而,这些方法需要生物不可信的成份,如详细储存老经验,以及长时间的离线学习。学习和利用字型的最佳方式仍是一个尚未解决的问题。从生物学得到启发后,我们建议做梦可能是使用内型的有效方便手段。我们建议建立一个双模(试剂和模型)的神经神经网络,在其中大大促进“呼吸”(在模型模拟环境中的新经验)的学习。我们还探索“规划”是一种在线梦想的替代方法,它显示类似的性能。重要的是,我们的模型并不要求详细储存经验,在网上学习世界模型和政策。此外,我们强调我们的网络是由神经元组成的,进一步增加神经形态硬件的生物可视性和可执行性。