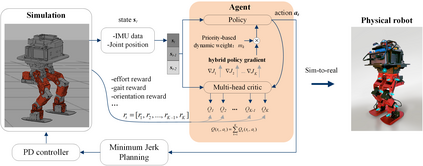
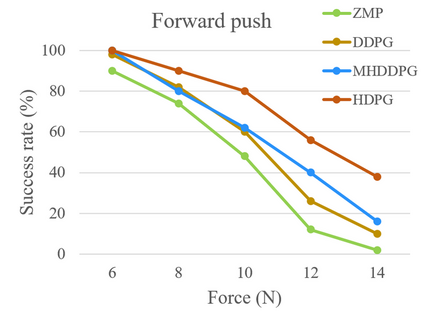
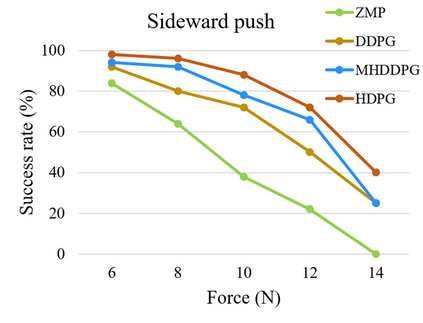
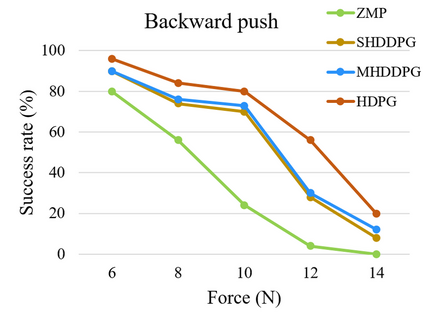
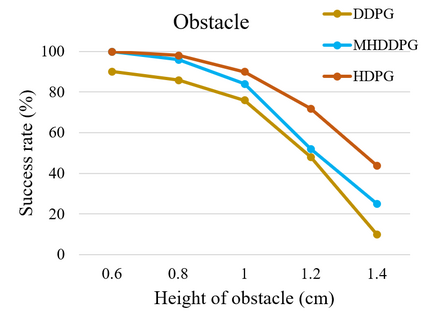
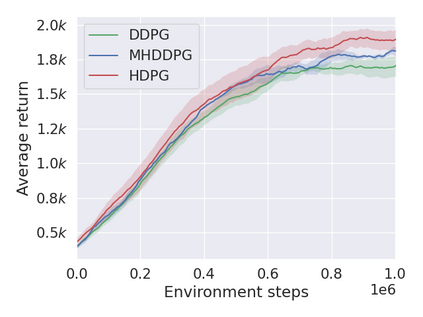
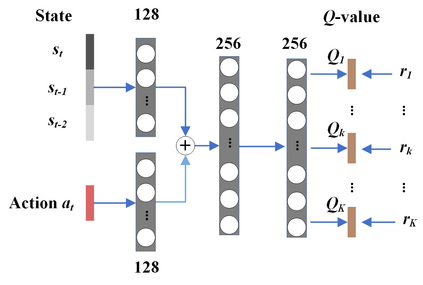
Controlling a non-statically bipedal robot is challenging due to the complex dynamics and multi-criterion optimization involved. Recent works have demonstrated the effectiveness of deep reinforcement learning (DRL) for simulation and physically implemented bipeds. In these methods, the rewards from different criteria are normally summed to learn a single value function. However, this may cause the loss of dependency information between hybrid rewards and lead to a sub-optimal policy. In this work, we propose a novel policy gradient reinforcement learning for biped locomotion, allowing the control policy to be simultaneously optimized by multiple criteria using a dynamic mechanism. Our proposed method applies a multi-head critic to learn a separate value function for each component reward function. This also leads to hybrid policy gradients. We further propose dynamic weight for hybrid policy gradients to optimize the policy with different priorities. This hybrid and dynamic policy gradient (HDPG) design makes the agent learn more efficiently. We showed that the proposed method outperforms summed-up-reward approaches and is able to transfer to physical robots. The MuJoCo results further demonstrate the effectiveness and generalization of our HDPG.
翻译:由于复杂的动态和多标准优化所涉及的复杂动态和多标准优化,控制非双极机器人具有挑战性。最近的工作表明,在模拟和实际执行的双胞胎方面,深强化学习(DRL)的效果是有效的。在这些方法中,不同标准的奖励通常被总结为学习一个单一的值函数。然而,这可能导致混合奖赏之间的依赖性信息丢失,并导致一个亚优政策。在这项工作中,我们提议为双双双斜体移动学习一种新的政策梯度强化学习,允许使用动态机制的多重标准对控制政策进行优化。我们提议的方法采用多头评论器,为每个部分奖励功能学习一个单独的值函数。这也导致混合政策梯度。我们进一步提出混合政策梯度的动态权重,以优化政策与不同优先事项的优化。这种混合和动态政策梯度的设计使代理方学习效率更高。我们显示,拟议的方法超越了加价加价方法,能够向物理机器人转移。MuJoco的结果进一步证明了我们的HDPG的有效性和普遍化。