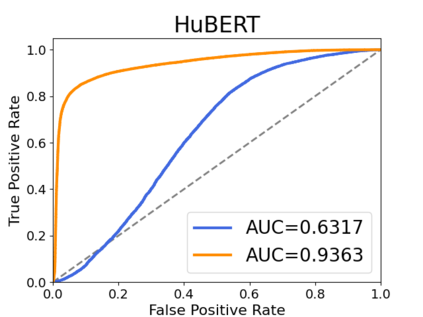
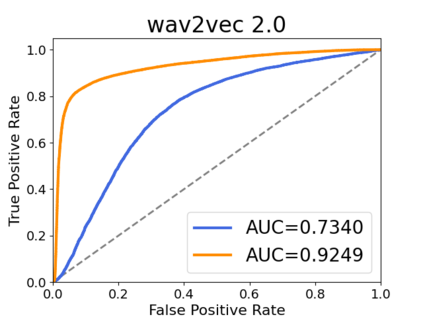
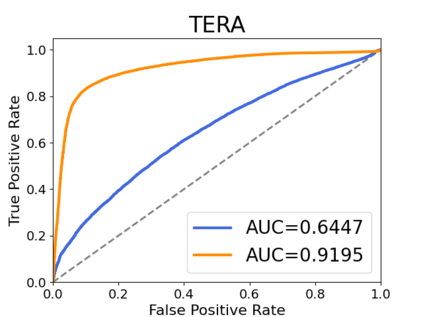
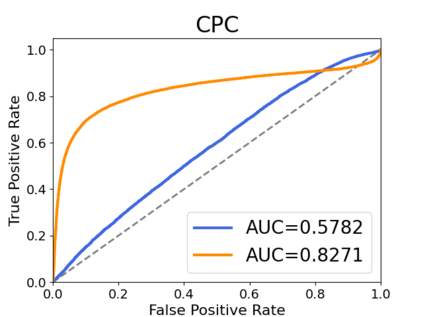
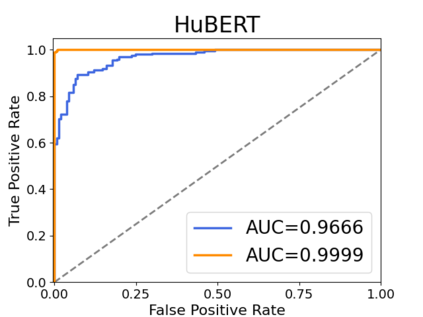
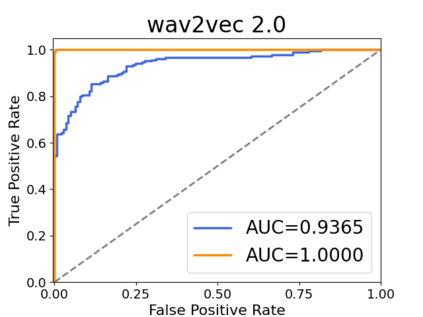
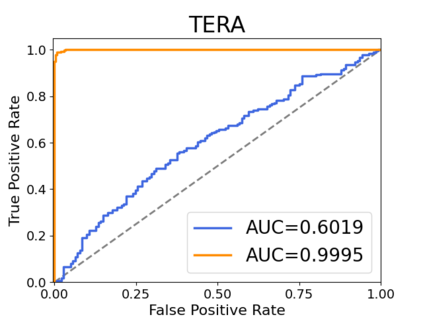
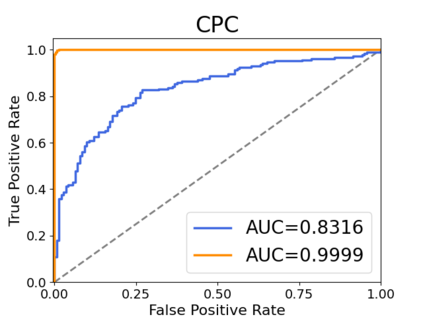
Recently, adapting the idea of self-supervised learning (SSL) on continuous speech has started gaining attention. SSL models pre-trained on a huge amount of unlabeled audio can generate general-purpose representations that benefit a wide variety of speech processing tasks. Despite their ubiquitous deployment, however, the potential privacy risks of these models have not been well investigated. In this paper, we present the first privacy analysis on several SSL speech models using Membership Inference Attacks (MIA) under black-box access. The experiment results show that these pre-trained models are vulnerable to MIA and prone to membership information leakage with high Area Under the Curve (AUC) in both utterance-level and speaker-level. Furthermore, we also conduct several ablation studies to understand the factors that contribute to the success of MIA.
翻译:最近,在连续演讲中自我监督学习(SSL)概念的调整开始引起人们的注意。 SSL模型在大量未贴标签的音频上预先培训,可以产生有利于多种语音处理任务的通用代表。尽管这些模式无处不在,但这些模式的潜在隐私风险尚未得到充分调查。在本文件中,我们首次对使用黑箱访问下的会员推断攻击(MIA)的多个SSL语言模型进行了隐私分析。实验结果表明,这些预先培训的模型很容易受到MIA的影响,而且很容易在言论和演讲级别与Curve(AUC)下高空区域发生会籍信息泄漏。此外,我们还进行了几项通缩研究,以了解有助于MIA成功的因素。