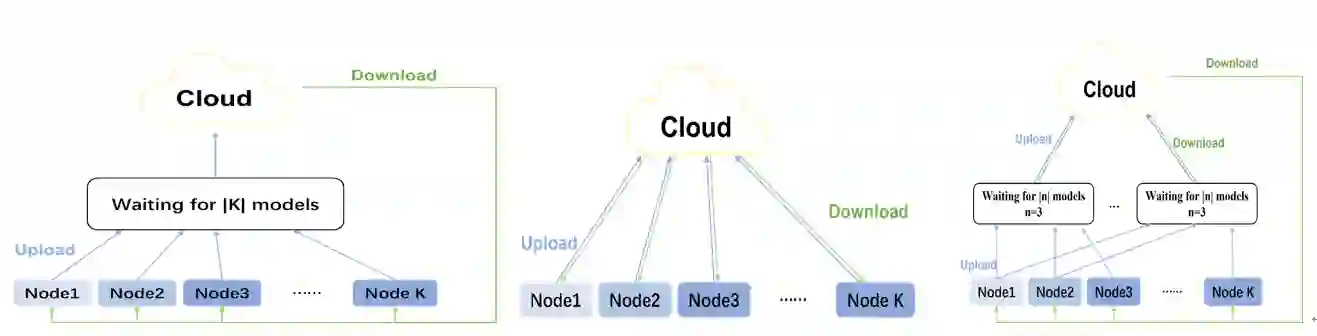
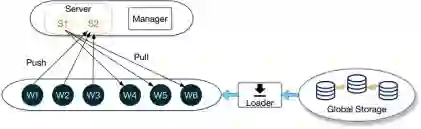
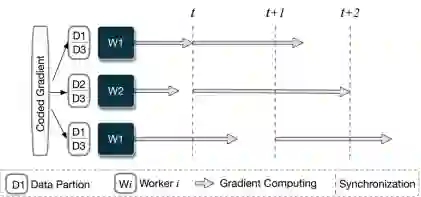
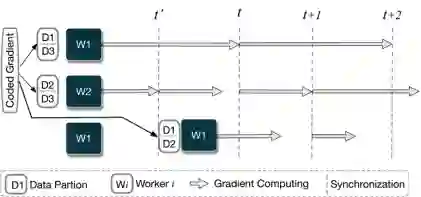
The widespread adoption of distributed learning to train a global model from local data has been hindered by the challenge posed by stragglers. Recent attempts to mitigate this issue through gradient coding have proved difficult due to the large amounts of data redundancy, computational and communicational overhead it brings. Additionally, the complexity of encoding and decoding increases linearly with the number of local workers. In this paper, we present a lightweight coding method for the computing phase and a fair transmission protocol for the communication phase, to mitigate the straggler problem. A two-stage dynamic coding scheme is proposed for the computing phase, where partial gradients are computed by a portion of workers in the first stage and the remainder are decided based on their completion status in the first stage. To ensure fair communication, a perturbed Lyapunov function is designed to balance admission data fairness and maximize throughput. Extensive experimental results demonstrate the superiority of our proposed solution in terms of accuracy and resource utilization in the distributed learning system, even under practical network conditions and benchmark data.
翻译:暂无翻译