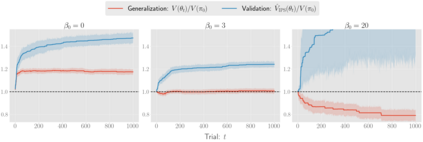
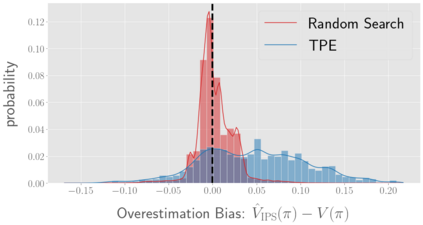
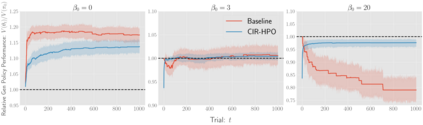
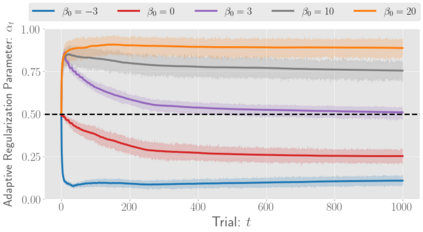
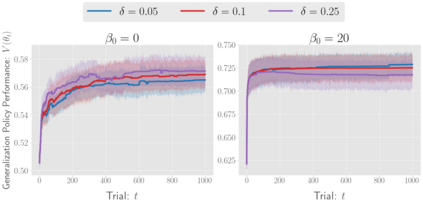
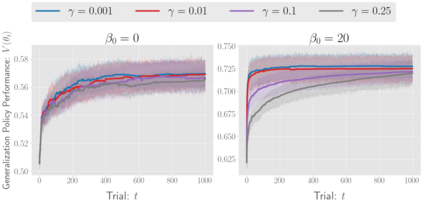
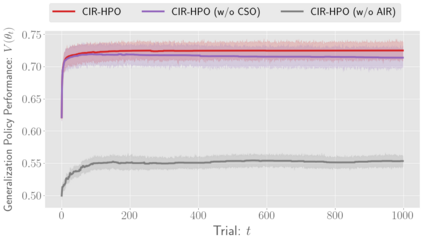
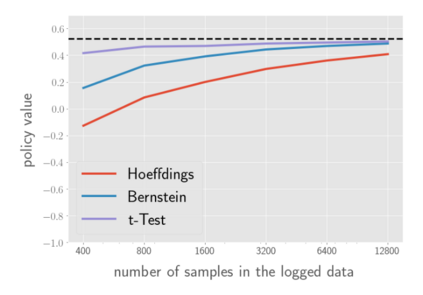
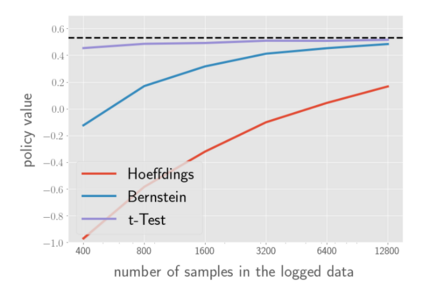
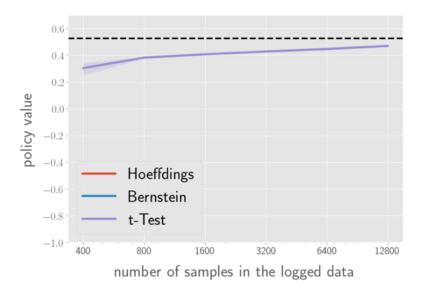
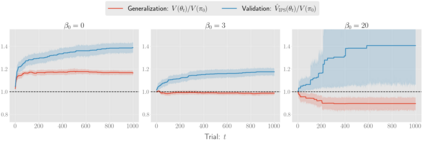
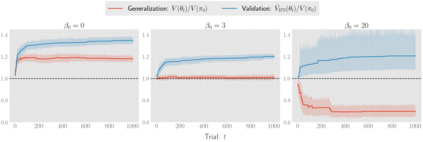
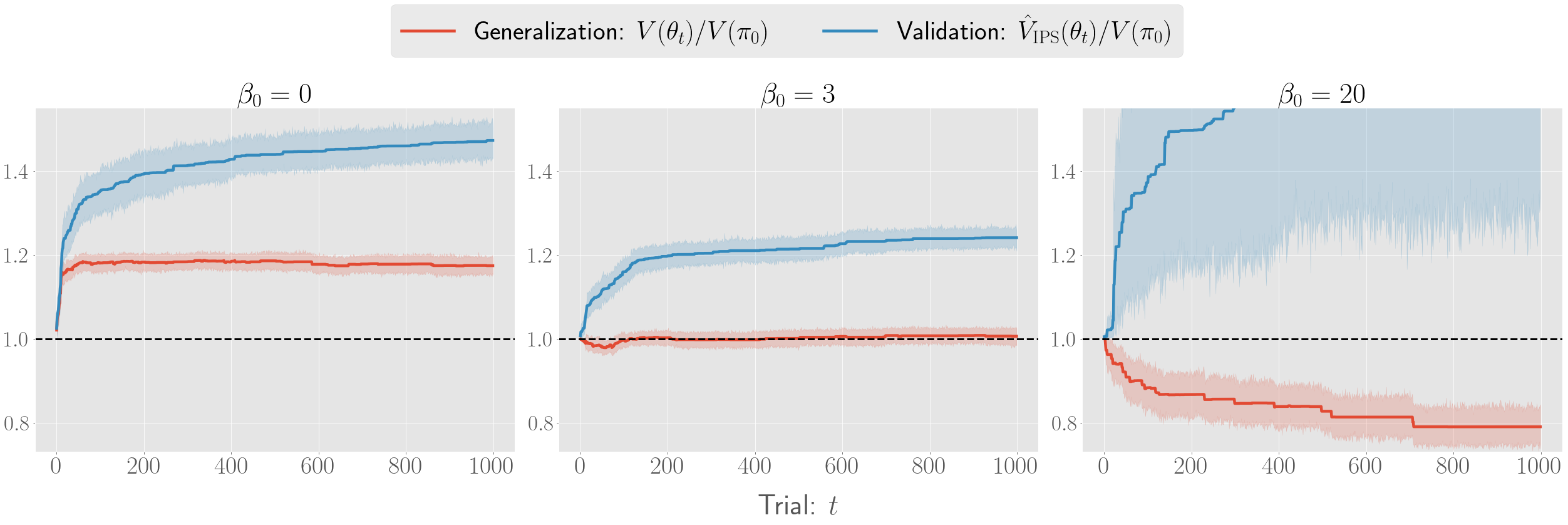
There has been a growing interest in off-policy evaluation in the literature such as recommender systems and personalized medicine. We have so far seen significant progress in developing estimators aimed at accurately estimating the effectiveness of counterfactual policies based on biased logged data. However, there are many cases where those estimators are used not only to evaluate the value of decision making policies but also to search for the best hyperparameters from a large candidate space. This work explores the latter hyperparameter optimization (HPO) task for off-policy learning. We empirically show that naively applying an unbiased estimator of the generalization performance as a surrogate objective in HPO can cause an unexpected failure, merely pursuing hyperparameters whose generalization performance is greatly overestimated. We then propose simple and computationally efficient corrections to the typical HPO procedure to deal with the aforementioned issues simultaneously. Empirical investigations demonstrate the effectiveness of our proposed HPO algorithm in situations where the typical procedure fails severely.
翻译:暂无翻译