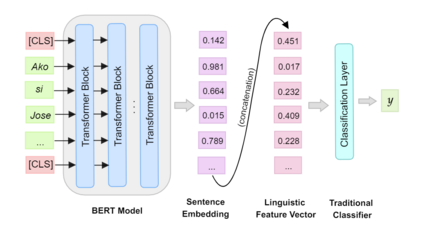
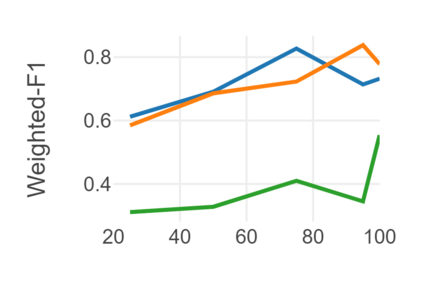
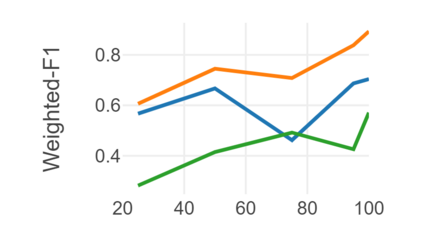
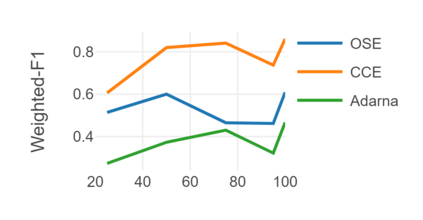
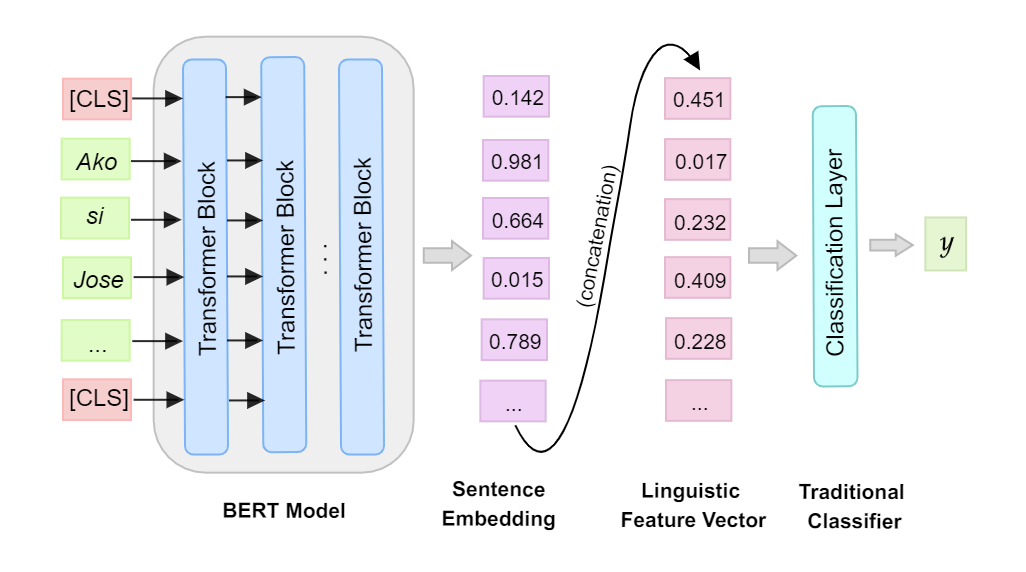
Automatic readability assessment (ARA) is the task of evaluating the level of ease or difficulty of text documents for a target audience. For researchers, one of the many open problems in the field is to make such models trained for the task show efficacy even for low-resource languages. In this study, we propose an alternative way of utilizing the information-rich embeddings of BERT models with handcrafted linguistic features through a combined method for readability assessment. Results show that the proposed method outperforms classical approaches in readability assessment using English and Filipino datasets, obtaining as high as 12.4% increase in F1 performance. We also show that the general information encoded in BERT embeddings can be used as a substitute feature set for low-resource languages like Filipino with limited semantic and syntactic NLP tools to explicitly extract feature values for the task.
翻译:自动可读性评估(ARA)是评估目标受众文本文件的易读性或难易程度的任务。对于研究人员来说,实地许多尚未解决的问题之一是使经过培训的任务模型显示出效力,即使是低资源语言也是如此。在本研究中,我们建议了另一种方法,通过综合易读性评估方法,利用手工艺语言特征的BERT模型中信息丰富的嵌入方式,利用人工制作的语言特征。结果显示,拟议方法在使用英语和菲律宾数据集进行可读性评估方面优于经典方法,在F1性能中取得了高达12.4%的增长。我们还表明,BERT嵌入中输入的一般信息可以用作菲律宾语等低资源语言的替代特征,菲律宾语的语具有有限的语义和合成NLP工具,以明确提取任务特性值。