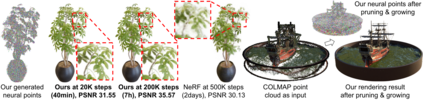
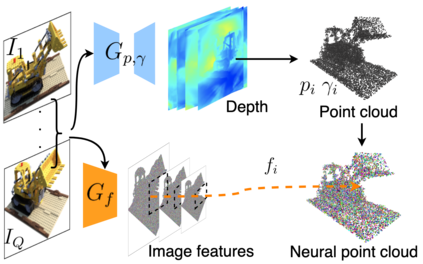
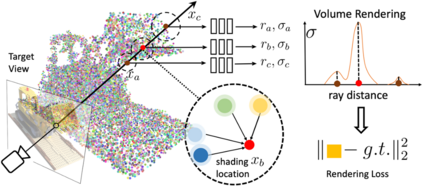
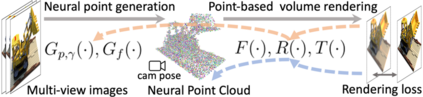
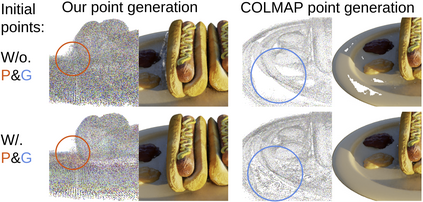
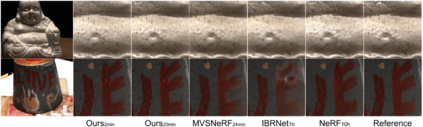
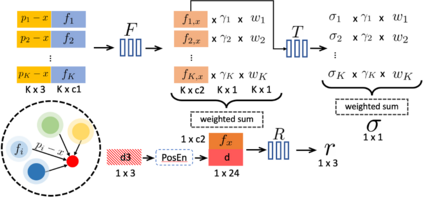
Volumetric neural rendering methods like NeRF generate high-quality view synthesis results but are optimized per-scene leading to prohibitive reconstruction time. On the other hand, deep multi-view stereo methods can quickly reconstruct scene geometry via direct network inference. Point-NeRF combines the advantages of these two approaches by using neural 3D point clouds, with associated neural features, to model a radiance field. Point-NeRF can be rendered efficiently by aggregating neural point features near scene surfaces, in a ray marching-based rendering pipeline. Moreover, Point-NeRF can be initialized via direct inference of a pre-trained deep network to produce a neural point cloud; this point cloud can be finetuned to surpass the visual quality of NeRF with 30X faster training time. Point-NeRF can be combined with other 3D reconstruction methods and handles the errors and outliers in such methods via a novel pruning and growing mechanism.
翻译:NeRF 等体积神经转换方法产生高质量的合成合成结果,但每层都得到优化,从而导致无法承受的重建时间。另一方面,深多视立体方法可以通过直接的网络推断迅速重建场景几何。Point-NeRF 利用神经3D点云和相关的神经特征将这两种方法的优点结合起来,以模拟一个亮度场。点-NERF 可以通过在以射向为基础的铺设管道中将近表面的神经点特征集成成,从而有效地实现。此外,点-NERF 可以通过直接推断预先训练的深层网络产生一个神经点云来初始化;这个点云可以调整,以超过NERF的视觉质量,使用30X更快的培训时间。点-NERF可以与其他3D重建方法相结合,并通过新编程和成长机制处理这些方法中的错误和外值。