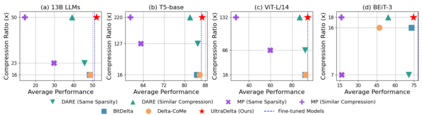
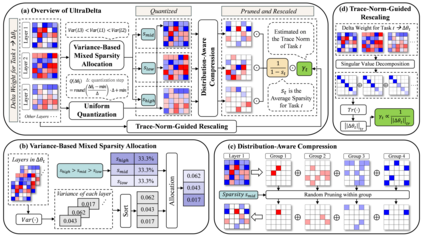
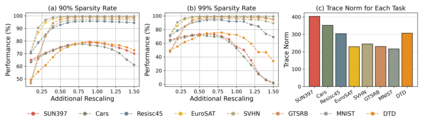
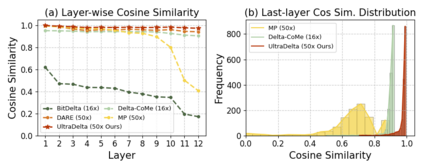
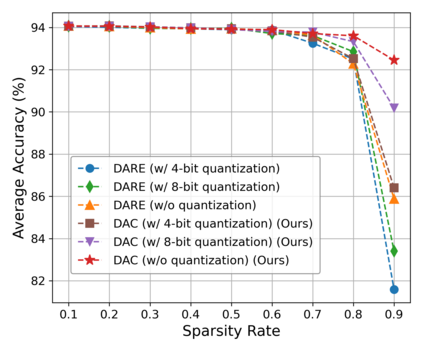
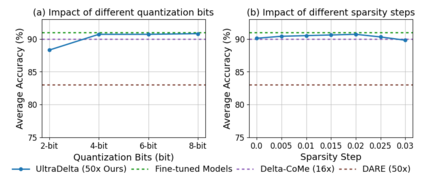
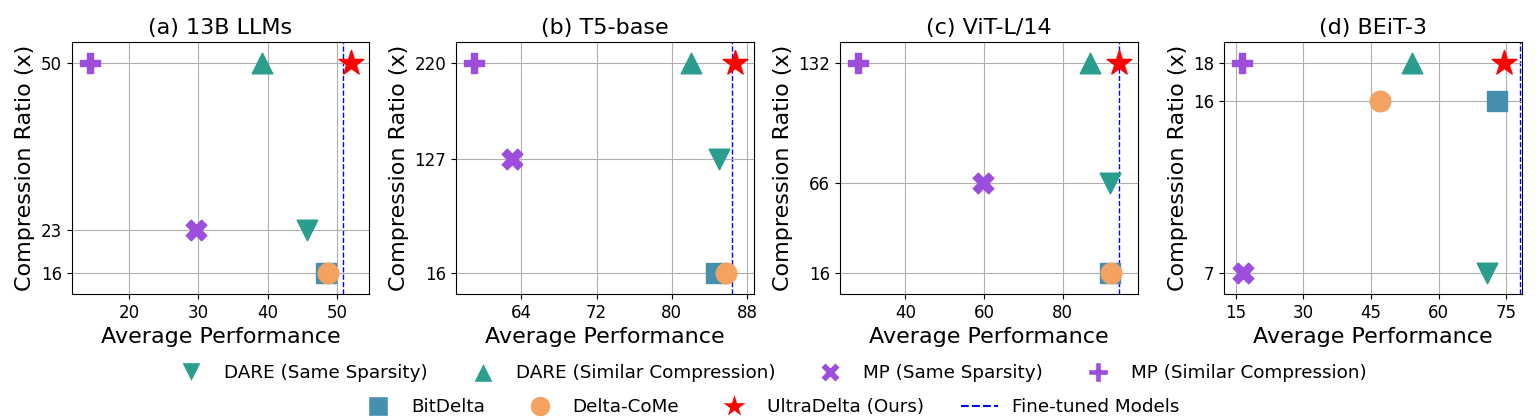
With the rise of the fine-tuned-pretrained paradigm, storing numerous fine-tuned models for multi-tasking creates significant storage overhead. Delta compression alleviates this by storing only the pretrained model and the highly compressed delta weights (the differences between fine-tuned and pretrained model weights). However, existing methods fail to maintain both high compression and performance, and often rely on data. To address these challenges, we propose UltraDelta, the first data-free delta compression pipeline that achieves both ultra-high compression and strong performance. UltraDelta is designed to minimize redundancy, maximize information, and stabilize performance across inter-layer, intra-layer, and global dimensions, using three key components: (1) Variance-Based Mixed Sparsity Allocation assigns sparsity based on variance, giving lower sparsity to high-variance layers to preserve inter-layer information. (2) Distribution-Aware Compression applies uniform quantization and then groups parameters by value, followed by group-wise pruning, to better preserve intra-layer distribution. (3) Trace-Norm-Guided Rescaling uses the trace norm of delta weights to estimate a global rescaling factor, improving model stability under higher compression. Extensive experiments across (a) large language models (fine-tuned on LLaMA-2 7B and 13B) with up to 50x compression, (b) general NLP models (RoBERTa-base, T5-base) with up to 224x compression, (c) vision models (ViT-B/32, ViT-L/14) with up to 132x compression, and (d) multi-modal models (BEiT-3) with 18x compression, demonstrate that UltraDelta consistently outperforms existing methods, especially under ultra-high compression. Code is available at https://github.com/xiaohuiwang000/UltraDelta.
翻译:暂无翻译