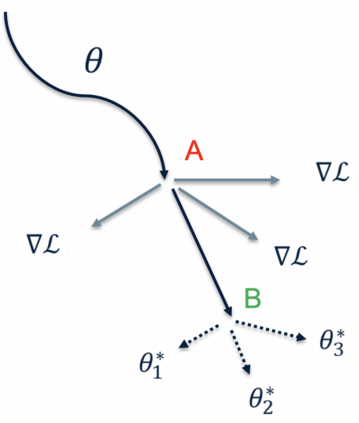
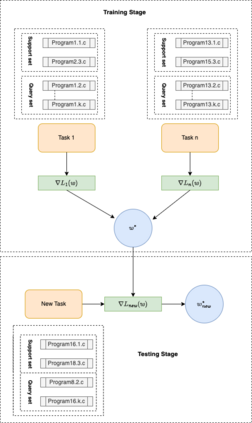
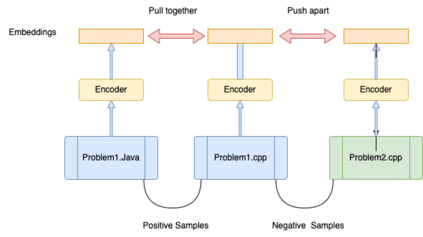
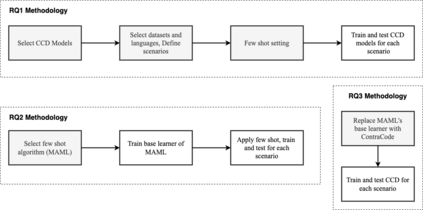
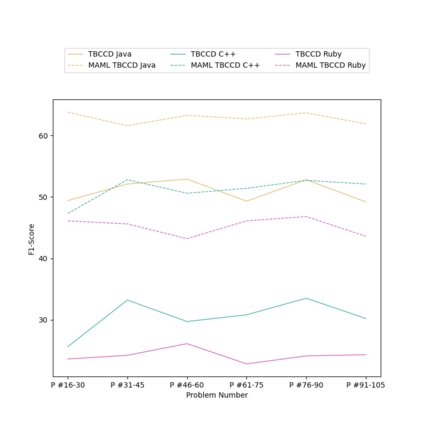
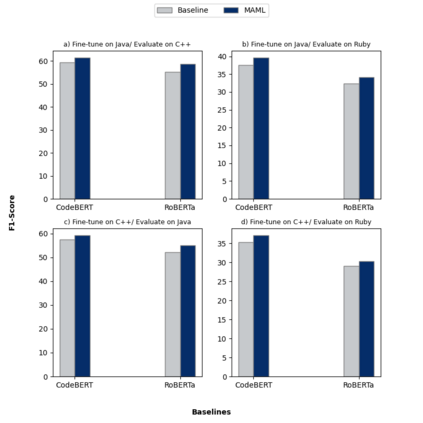
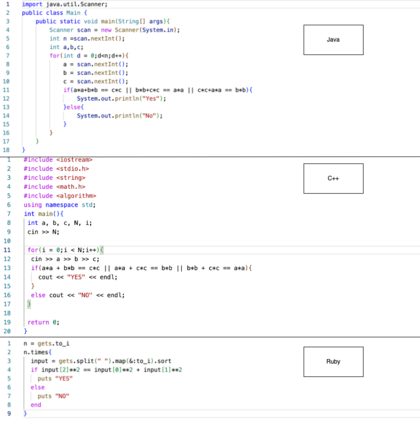
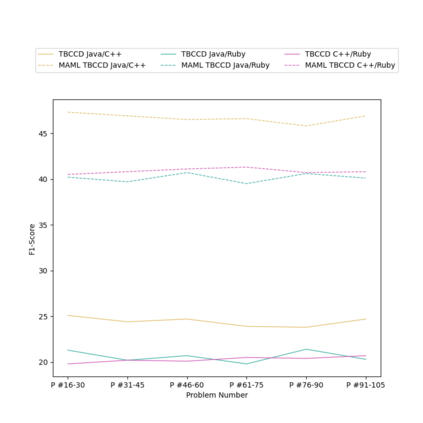
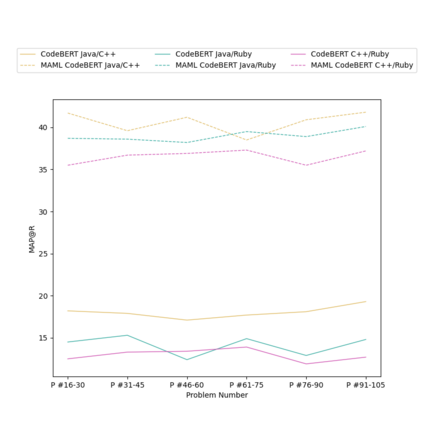
Context: Code Clone Detection (CCD) is a software engineering task that is used for plagiarism detection, code search, and code comprehension. Recently, deep learning-based models have achieved an F1 score (a metric used to assess classifiers) of $\sim$95\% on the CodeXGLUE benchmark. These models require many training data, mainly fine-tuned on Java or C++ datasets. However, no previous study evaluates the generalizability of these models where a limited amount of annotated data is available. Objective: The main objective of this research is to assess the ability of the CCD models as well as few shot learning algorithms for unseen programming problems and new languages (i.e., the model is not trained on these problems/languages). Method: We assess the generalizability of the state of the art models for CCD in few shot settings (i.e., only a few samples are available for fine-tuning) by setting three scenarios: i) unseen problems, ii) unseen languages, iii) combination of new languages and new problems. We choose three datasets of BigCloneBench, POJ-104, and CodeNet and Java, C++, and Ruby languages. Then, we employ Model Agnostic Meta-learning (MAML), where the model learns a meta-learner capable of extracting transferable knowledge from the train set; so that the model can be fine-tuned using a few samples. Finally, we combine contrastive learning with MAML to further study whether it can improve the results of MAML.
翻译:暂无翻译