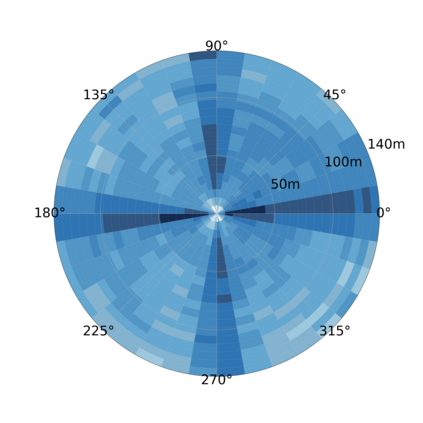
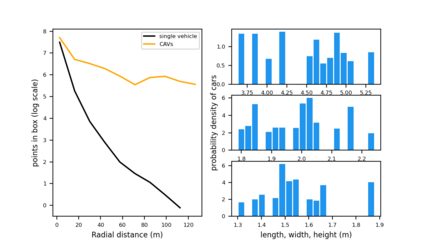
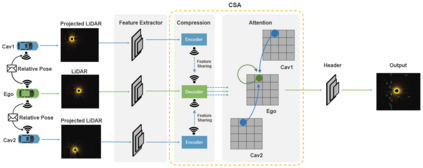
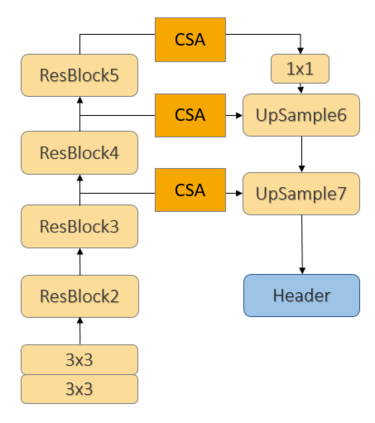
Employing Vehicle-to-Vehicle communication to enhance perception performance in self-driving technology has attracted considerable attention recently; however, the absence of a suitable open dataset for benchmarking algorithms has made it difficult to develop and assess cooperative perception technologies. To this end, we present the first large-scale open simulated dataset for Vehicle-to-Vehicle perception. It contains over 70 interesting scenes, 11,464 frames, and 232,913 annotated 3D vehicle bounding boxes, collected from 8 towns in CARLA and a digital town of Culver City, Los Angeles. We then construct a comprehensive benchmark with a total of 16 implemented models to evaluate several information fusion strategies~(i.e. early, late, and intermediate fusion) with state-of-the-art LiDAR detection algorithms. Moreover, we propose a new Attentive Intermediate Fusion pipeline to aggregate information from multiple connected vehicles. Our experiments show that the proposed pipeline can be easily integrated with existing 3D LiDAR detectors and achieve outstanding performance even with large compression rates. To encourage more researchers to investigate Vehicle-to-Vehicle perception, we will release the dataset, benchmark methods, and all related codes in https://mobility-lab.seas.ucla.edu/opv2v/.
翻译:最近,利用车辆到车辆的通信来提高自我驾驶技术的认知性能,引起了相当多的注意;然而,由于缺乏一个适当的基准算法的开放数据集,因此很难开发和评估合作的认知技术;为此,我们提出了第一个车辆到车辆的认知大规模开放模拟数据集,其中包括70多个有趣的场景、11 464个框架和232 913个附加说明的3D车辆装箱,这些装箱是从CARLA的8个城镇和洛杉矶Culver市的一个数字城镇收集的,我们随后建立了一个综合基准,共有16个执行模型,用以评价若干信息集成战略~(即早期、晚期和中间集成),并配有最先进的LIDAR检测算法。此外,我们提议建立一个新的“加速中间集散”管道,用于收集多部相关车辆的信息。我们的实验表明,拟议的管道可以很容易与现有的3D LiDAR探测器和高压率的数码城市取得杰出的性能。我们鼓励更多的研究人员调查车辆-飞行器-飞行器的感知觉觉觉觉觉觉,我们将公布有关数据/代谢标准。