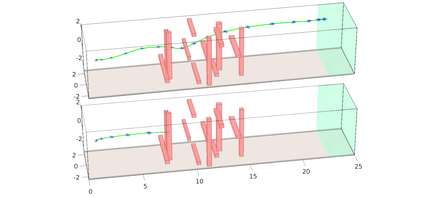
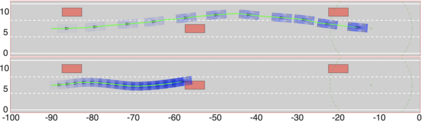
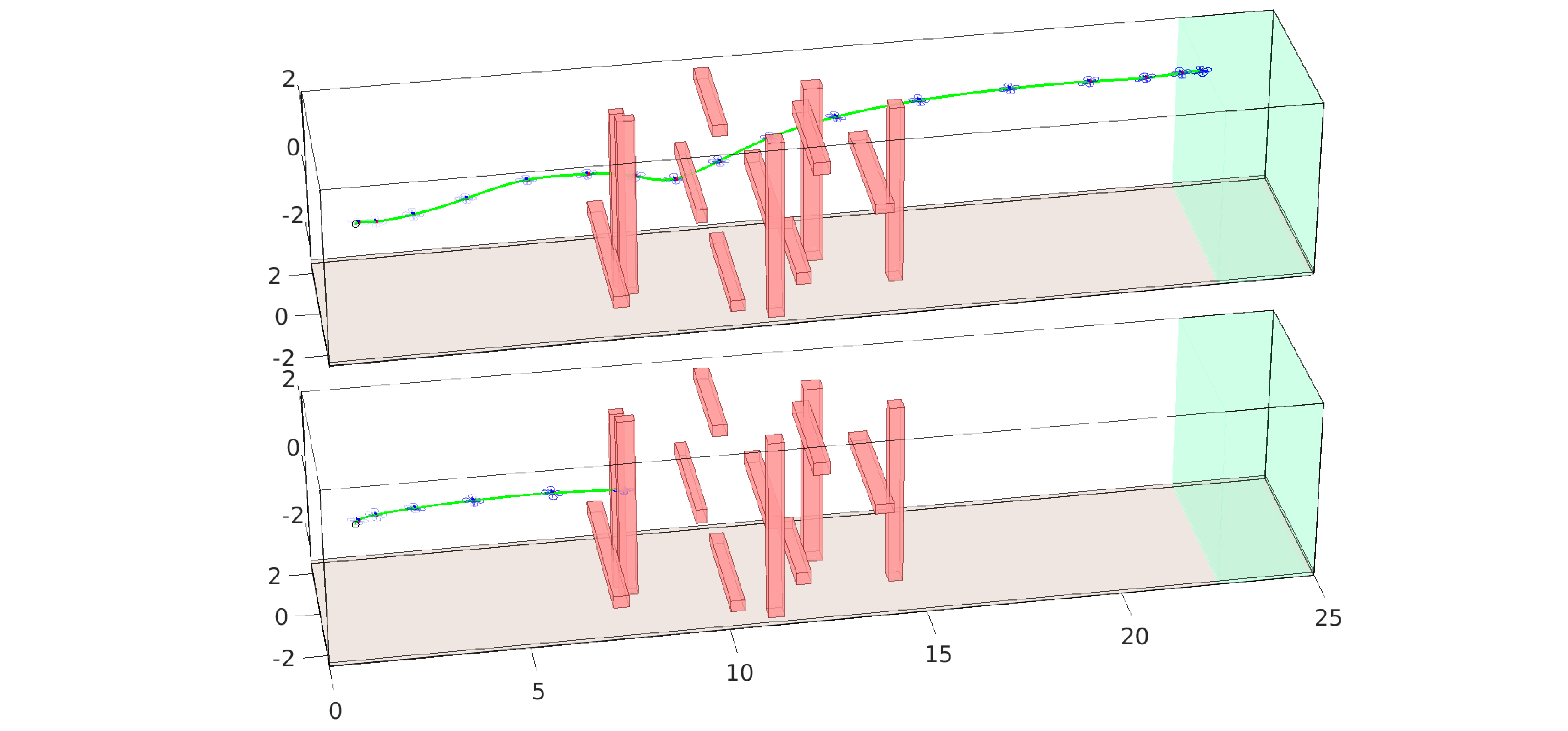
Reinforcement Learning (RL) algorithms have achieved remarkable performance in decision making and control tasks due to their ability to reason about long-term, cumulative reward using trial and error. However, during RL training, applying this trial-and-error approach to real-world robots operating in safety critical environment may lead to collisions. To address this challenge, this paper proposes a Reachability-based Trajectory Safeguard (RTS), which leverages reachability analysis to ensure safety during training and operation. Given a known (but uncertain) model of a robot, RTS precomputes a Forward Reachable Set of the robot tracking a continuum of parameterized trajectories. At runtime, the RL agent selects from this continuum in a receding-horizon way to control the robot; the FRS is used to identify if the agent's choice is safe or not, and to adjust unsafe choices. The efficacy of this method is illustrated on three nonlinear robot models, including a 12-D quadrotor drone, in simulation and in comparison with state-of-the-art safe motion planning methods.
翻译:强化学习(RL)算法在决策和控制任务方面取得了显著的成绩,这是因为他们有能力利用试验和错误来解释长期、累积的奖赏。但是,在RL培训期间,对在安全临界环境中操作的现实世界机器人应用这种试和试方法可能会导致碰撞。为了应对这一挑战,本文件建议采用基于可变性的轨迹保护(RTS),利用可变性分析来确保培训和操作期间的安全。考虑到已知的(但不确定的)机器人模型,RTS预先计算了机器人的可前向可达数据集,跟踪参数化轨迹的连续体。在运行时,RL代理商从这一连续体中选择一种递减-正态方法来控制机器人;FRS用来确定该代理人的选择是否安全或不安全,并调整不安全的选择。这一方法的功效在三种非线性机器人模型上作了说明,包括12D孔德无人驾驶飞机,在模拟和与州级安全运动规划方法进行比较。