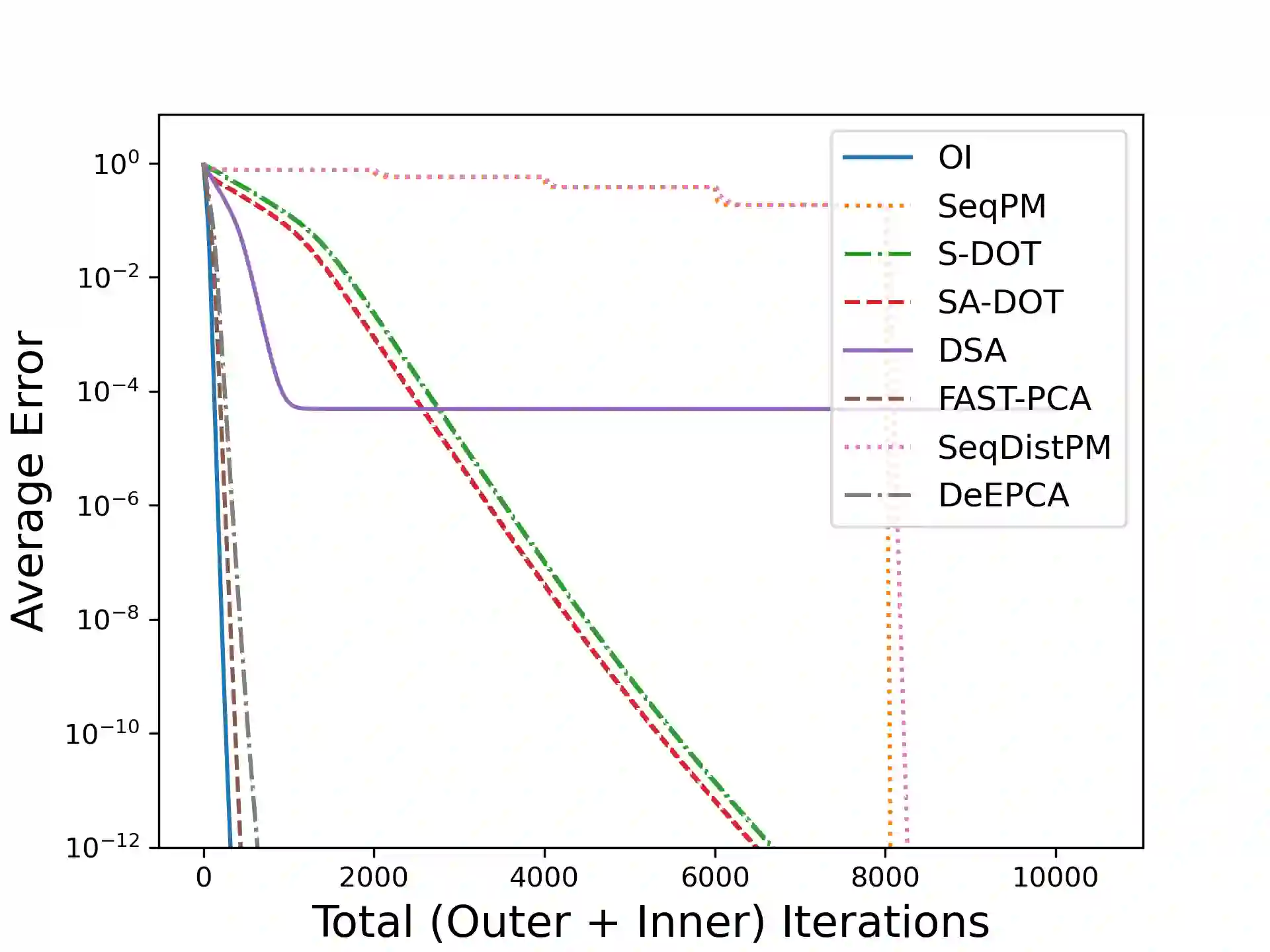
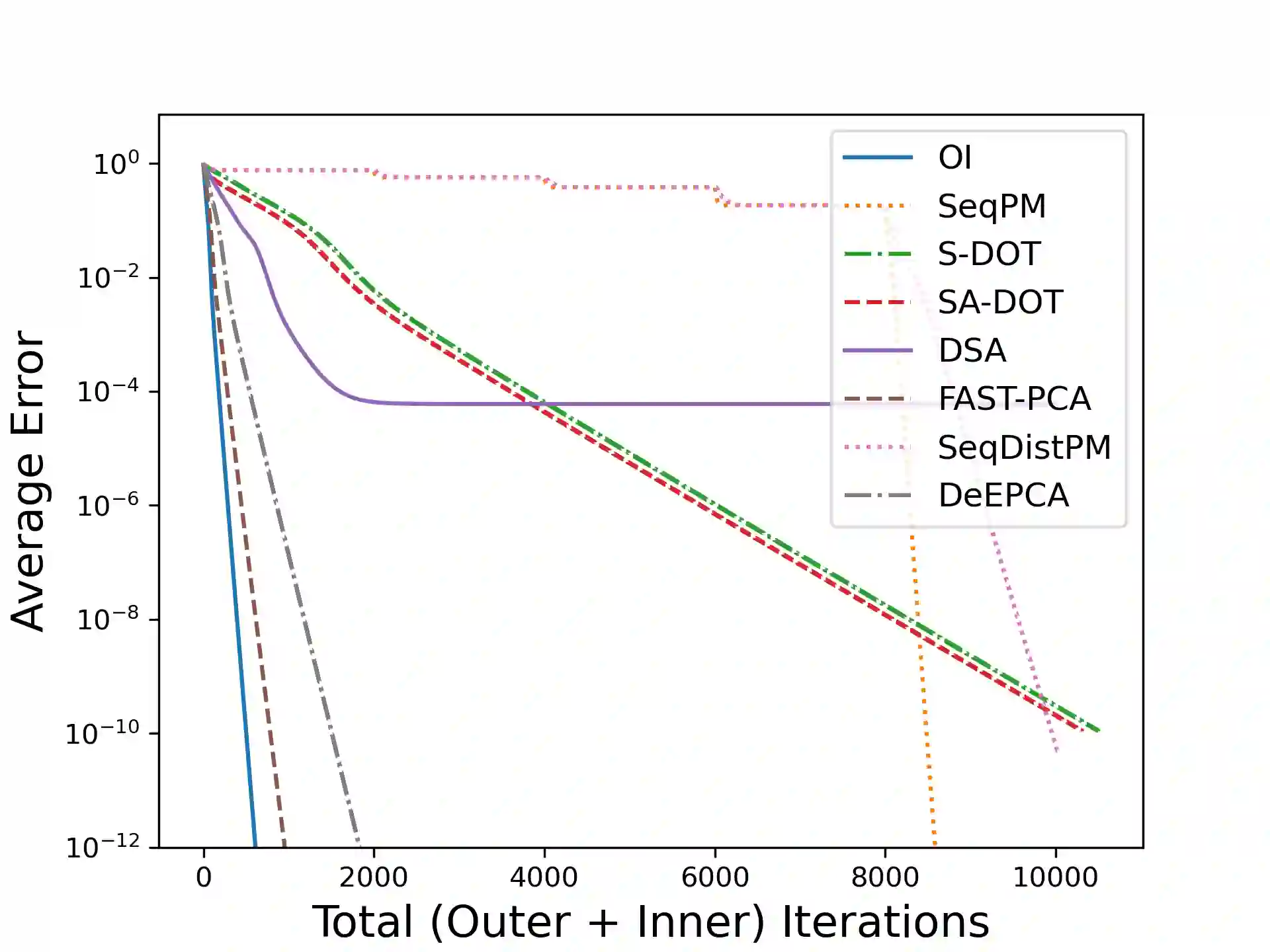
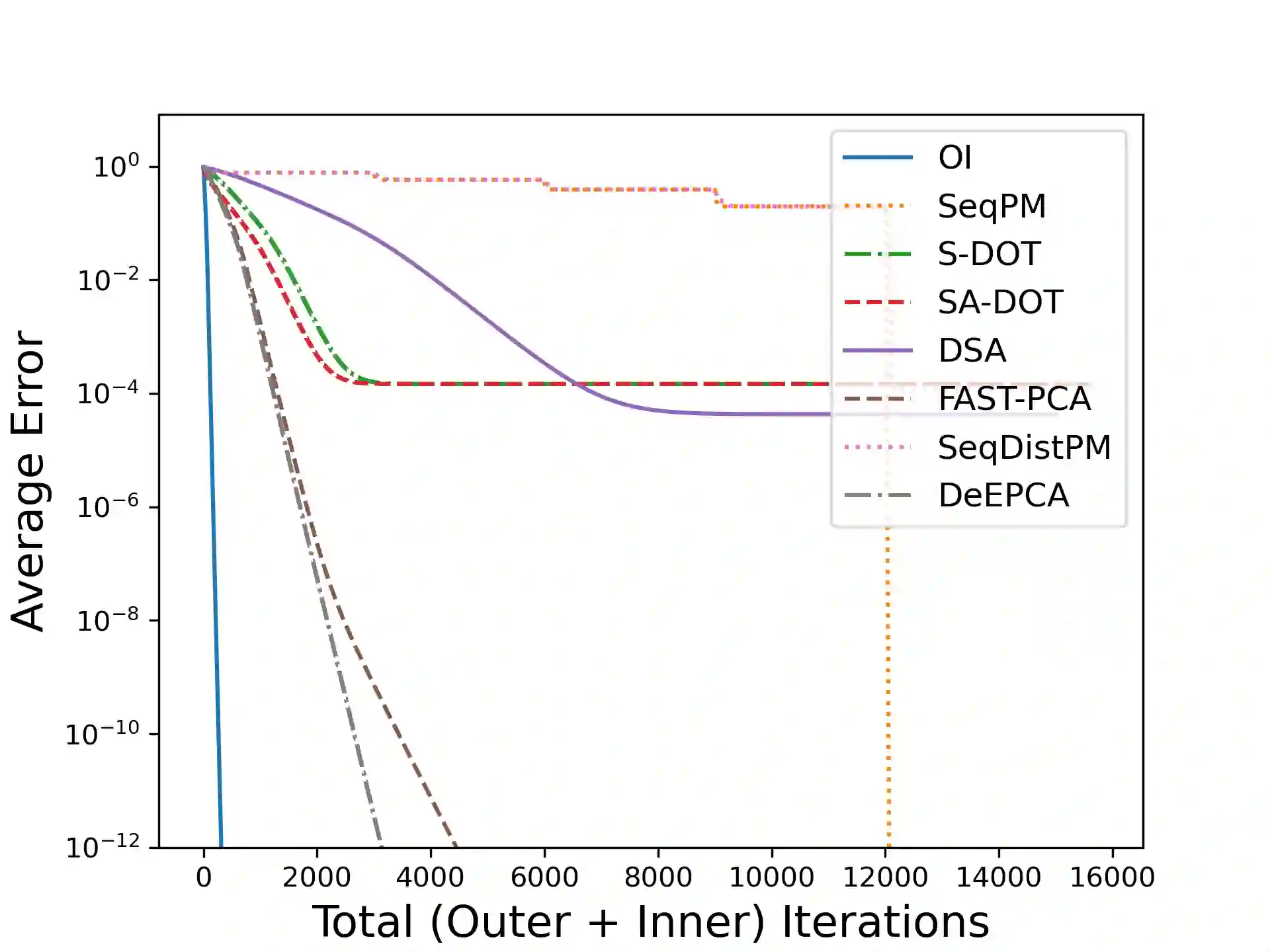
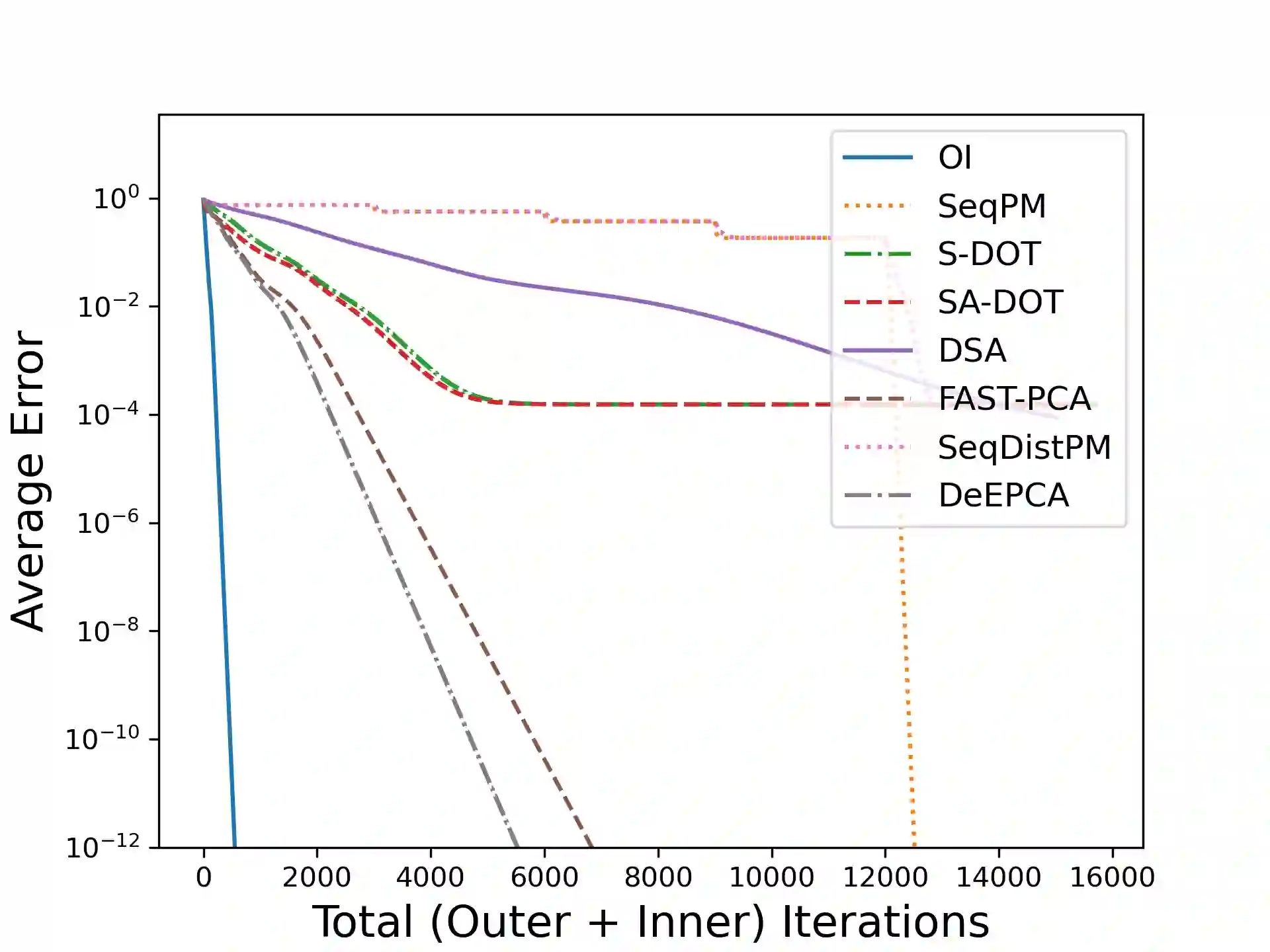
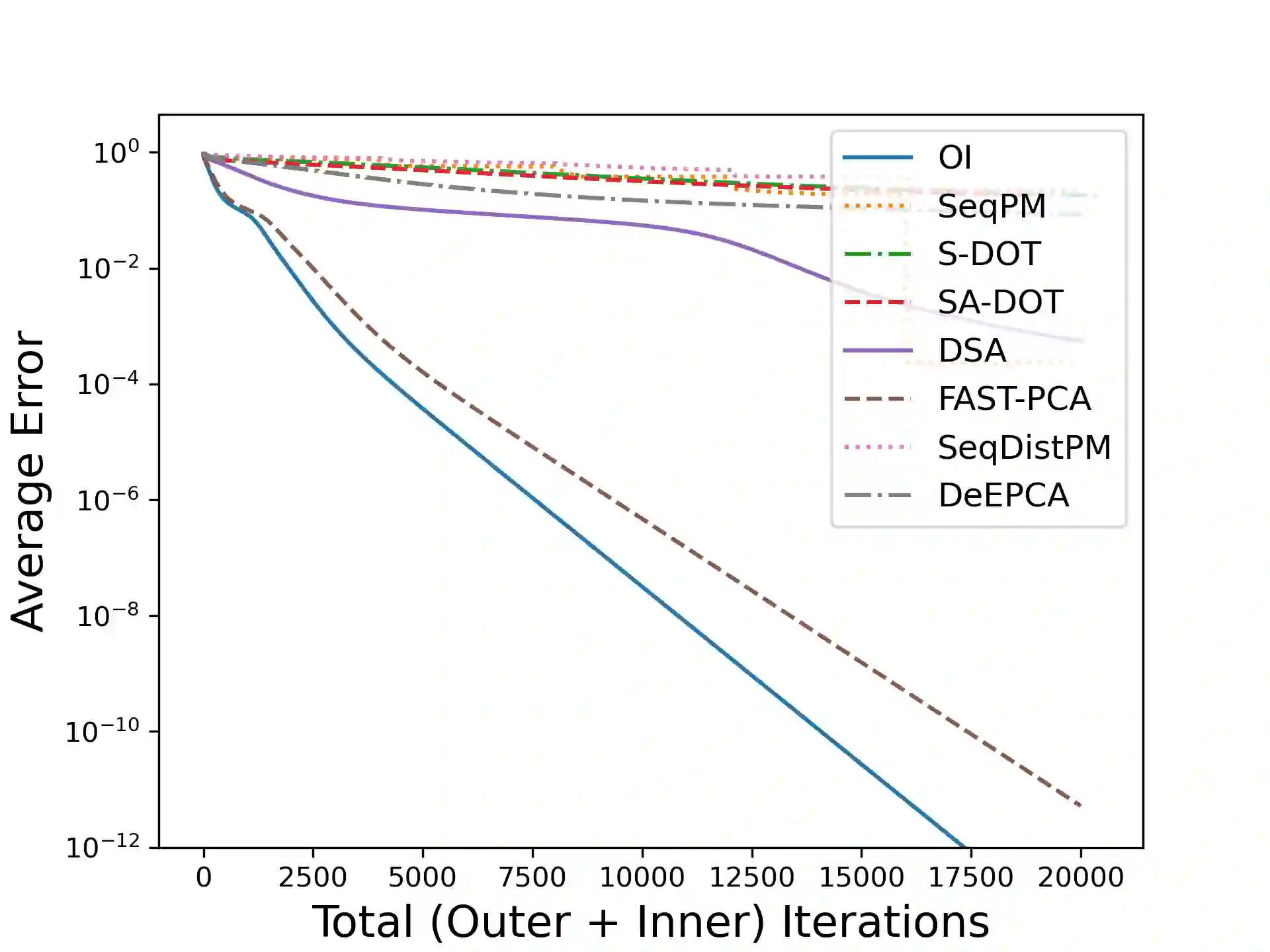
Principal Component Analysis (PCA) is a fundamental data preprocessing tool in the world of machine learning. While PCA is often reduced to dimension reduction, the purpose of PCA is actually two-fold: dimension reduction and feature learning. Furthermore, the enormity of the dimensions and sample size in the modern day datasets have rendered the centralized PCA solutions unusable. In that vein, this paper reconsiders the problem of PCA when data samples are distributed across nodes in an arbitrarily connected network. While a few solutions for distributed PCA exist those either overlook the feature learning part of the purpose, have communication overhead making them inefficient and/or lack exact convergence guarantees. To combat these aforementioned issues, this paper proposes a distributed PCA algorithm called FAST-PCA (Fast and exAct diSTributed PCA). The proposed algorithm is efficient in terms of communication and can be proved to converge linearly and exactly to the principal components that lead to dimension reduction as well as uncorrelated features. Our claims are further supported by experimental results.
翻译:计算机学习世界中,主要组成部分分析(PCA)是基本的数据预处理工具,虽然五氯苯甲醚通常会降低其尺寸,但五氯苯甲醚的目的实际上是双重的:减少尺寸和特征学习;此外,现代数据集中方方面面和样本规模之大,使得中央化的五氯苯甲醚解决方案无法使用;因此,本文件重新考虑了在任意连接的网络中将数据样品分布在一个节点上时五氯苯甲醚的问题;虽然分布式五氯苯甲醚的几种解决办法要么忽视了该目的的特征学习部分,要么有通信间接费用,使其效率低下和/或缺乏精确的趋同保证;为了解决上述问题,本文件建议采用一个分布式的五氯苯甲醚算法,称为FAST-PCA(远端和前端端端端法律五氯苯甲甲醚);拟议的算法在通信方面是有效的,可以被证明可以直线地和完全结合到导致减少尺寸和不相干的特点的主要组成部分。我们的索赔得到实验结果的进一步支持。