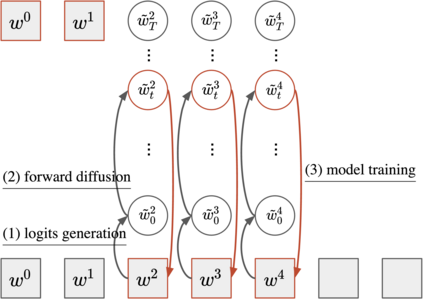
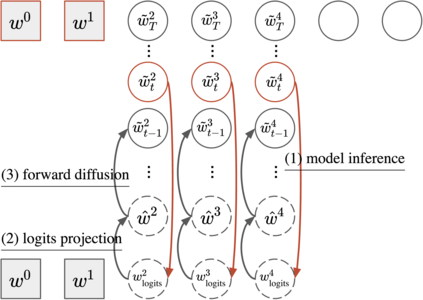
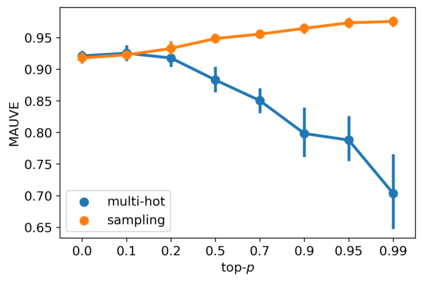
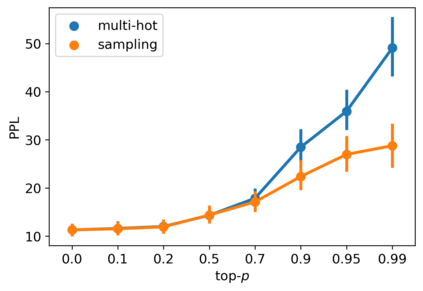
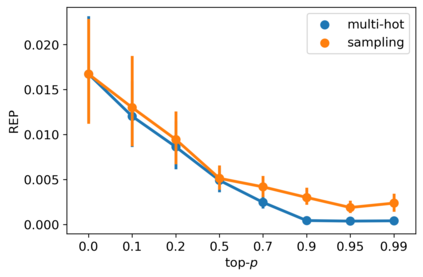
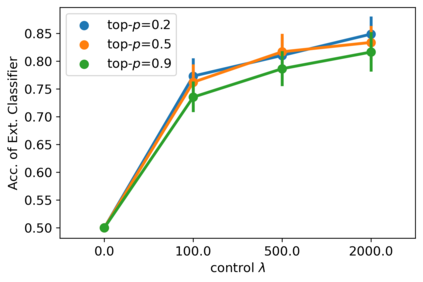
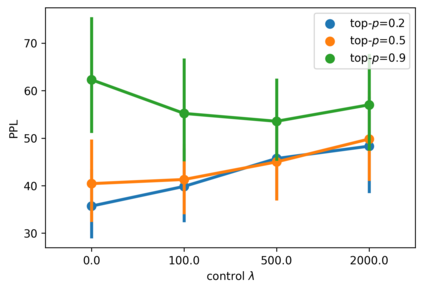
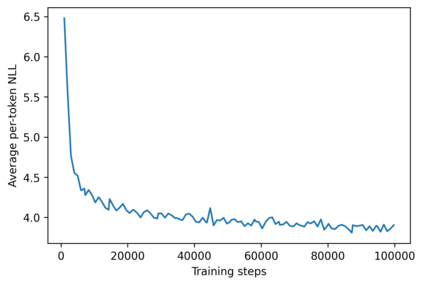
Despite the growing success of diffusion models in continuous-valued domains (e.g., images), diffusion-based language models on discrete text have yet to match autoregressive language models on text generation benchmarks. In this work, we present SSD-LM -- a diffusion language model with two key design choices. First, SSD-LM is semi-autoregressive, iteratively generating blocks of text, allowing for flexible output length at decoding time while enabling local bidirectional context updates. Second, it is simplex-based, performing diffusion on the natural vocabulary space rather than a learned latent space, allowing us to incorporate classifier guidance and modular control without any adaptation of off-the-shelf classifiers. We evaluate SSD-LM on unconstrained as well as controlled text generation benchmarks, and show that it matches or outperforms strong autoregressive GPT-2 baselines across standard quality and diversity metrics.
翻译:尽管连续价值域(如图像)的传播模型日益成功,但关于离散文本的传播语言模型尚未在文本生成基准上与自动递减语言模型相匹配。在这项工作中,我们介绍了SSD-LM -- -- 一种具有两种关键设计选择的传播语言模型。首先,SSD-LM是半自动递增、迭代生成的文本块,允许在解码时使用灵活的输出长度,同时允许本地双向环境更新。第二,它基于简单x,在自然词汇空间上进行传播,而不是学习的潜伏空间上进行传播,使我们能够纳入分类制导和模块控制,而不对现成的分类式分类师进行任何调整。我们根据不受约束和控制的文本生成基准对SSD-LM进行了评估,并表明它与标准质量和多样性指标之间强大的自动递增的GPT-2基线相匹配或超出。