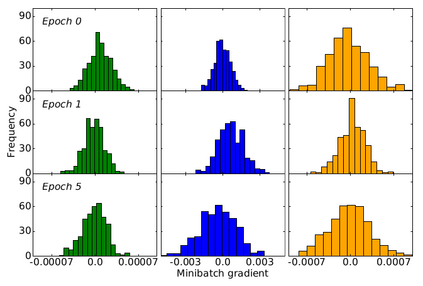
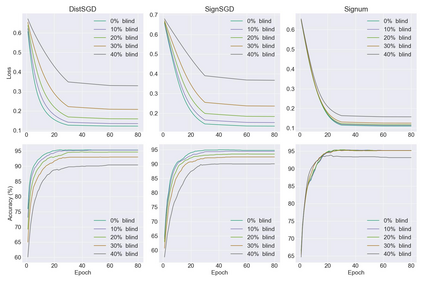
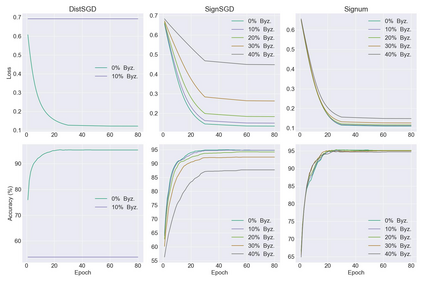
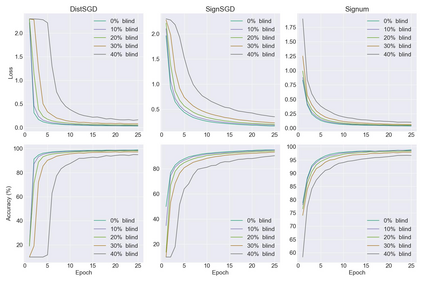
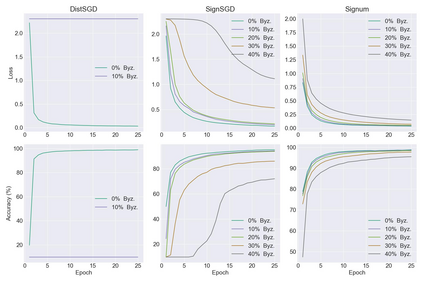
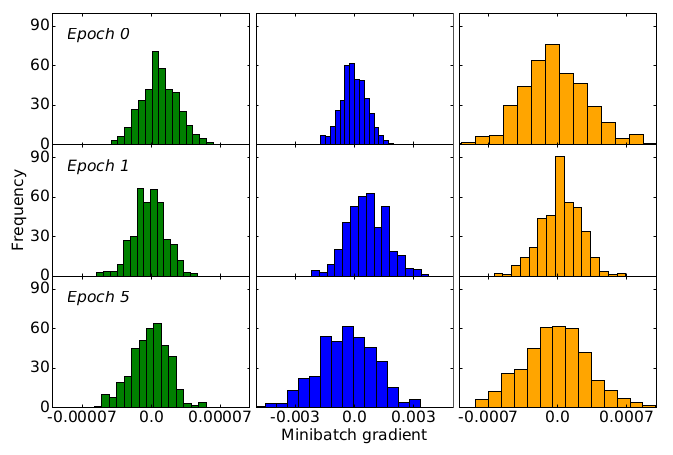
Distributed learning has become a necessity for training ever-growing models by sharing calculation among several devices. However, some of the devices can be faulty, deliberately or not, preventing the proper convergence. As a matter of fact, the baseline distributed SGD algorithm does not converge in the presence of one Byzantine adversary. In this article we focus on the more robust SignSGD algorithm derived from SGD. We provide an upper bound for the convergence rate of SignSGD proving that this new version is robust to Byzantine adversaries. We implemented SignSGD along with Byzantine strategies attempting to crush the learning process. Therefore, we provide empirical observations from our experiments to support our theory. Our code is available on GitHub https://github.com/jasonakoun/signsgd-fault-tolerance and our experiments are reproducible by using the provided parameters.
翻译:分散的学习已成为通过在几种装置之间共享计算方法来培训不断增长的模型的必要条件。 但是,有些装置可能有意或无意地有缺陷,从而阻止了适当的趋同。 事实上,基准分布的SGD算法在一个拜占庭对手在场的情况下并不汇合。 在本篇文章中,我们把重点放在由SGD产生的更强大的SignSGD算法上。我们为SignSGD的趋同率提供了一个上限,证明这个新版本对拜占庭对手是强大的。我们实施了SignSGD和Byzantine战略,试图粉碎学习过程。因此,我们从实验中提供了经验性观察,以支持我们的理论。我们的代码可以在GitHub https://github.com/jasonakun/ignsgd-falt容忍中找到,我们实验可以通过提供参数来重新制作。