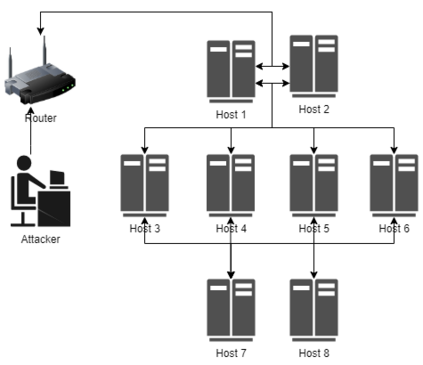
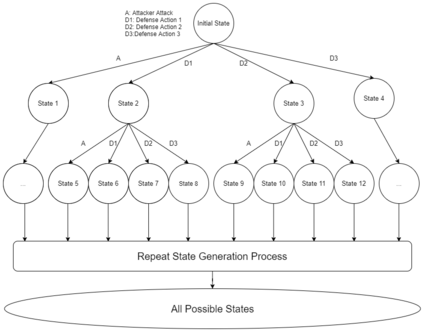
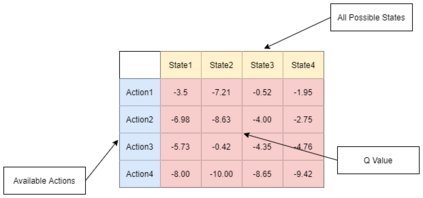
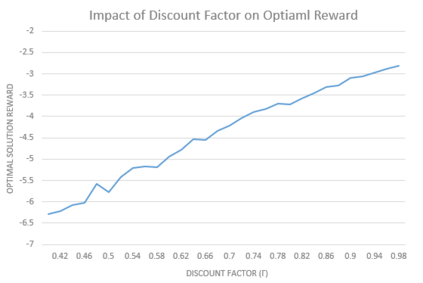
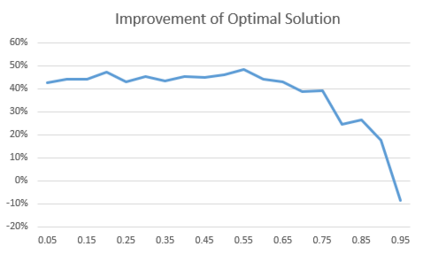
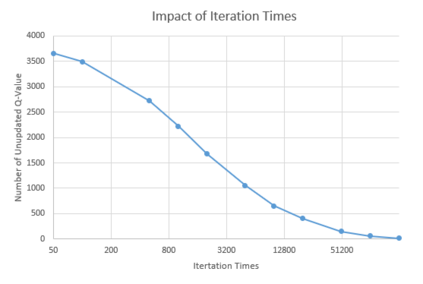
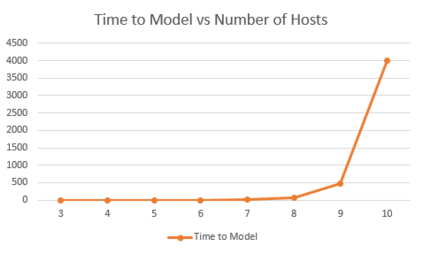
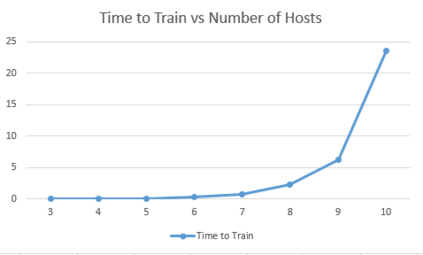
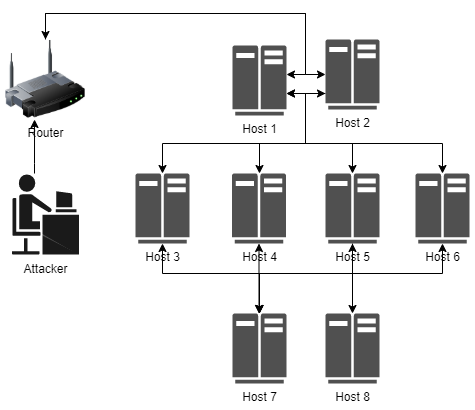
It is challenging for a security analyst to detect or defend against cyber-attacks. Moreover, traditional defense deployment methods require the security analyst to manually enforce the defenses in the presence of uncertainties about the defense to deploy. As a result, it is essential to develop an automated and resilient defense deployment mechanism to thwart the new generation of attacks. In this paper, we propose a framework based on Markov Decision Process (MDP) and Q-learning to automatically generate optimal defense solutions for networked system states. The framework consists of four phases namely; the model initialization phase, model generation phase, Q-learning phase, and the conclusion phase. The proposed model collects real network information as inputs and then builds them into structural data. We implement a Q-learning process in the model to learn the quality of a defense action in a particular state. To investigate the feasibility of the proposed model, we perform simulation experiments and the result reveals that the model can reduce the risk of network systems from cyber attacks. Furthermore, the experiment shows that the model has shown a certain level of flexibility when different parameters are used for Q-learning.
翻译:此外,传统的国防部署方法要求安全分析师在国防部署存在不确定性的情况下手动实施防御。因此,必须开发一个自动和有弹性的国防部署机制,以挫败新一代袭击。在本文件中,我们提议了一个基于Markov决策程序和Q学习的框架,以自动为联网系统国家产生最佳防御解决方案。框架由四个阶段组成,即:模型初始化阶段、模型生成阶段、Q-学习阶段和结束阶段。拟议的模型收集真实的网络信息,作为投入,然后将其建立为结构数据。我们在模型中实施一个学习过程,以学习特定国家防卫行动的质量。为了调查拟议模型的可行性,我们进行模拟实验,结果显示模型可以减少网络系统受到网络袭击的风险。此外,实验表明,当使用不同参数进行Q-学习时,模型显示出一定的灵活性。