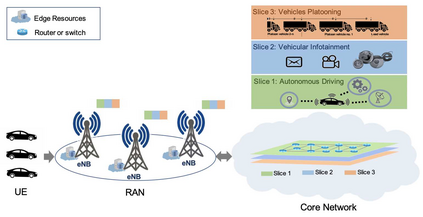
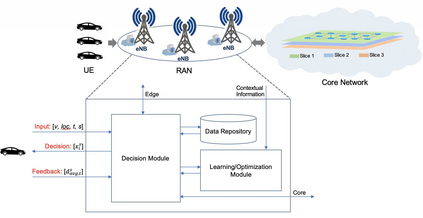
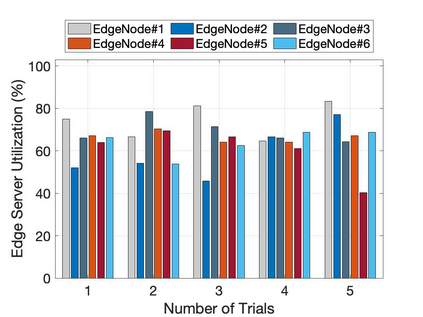
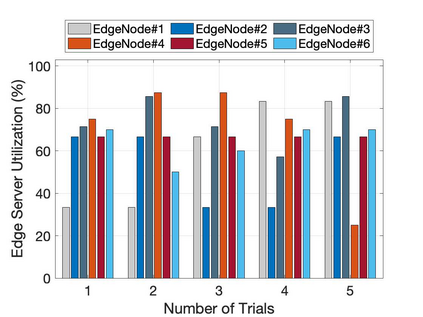
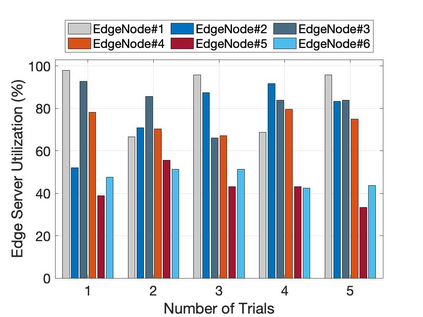
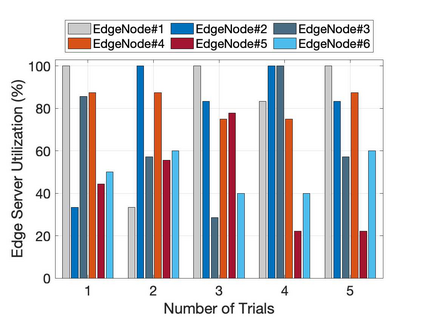
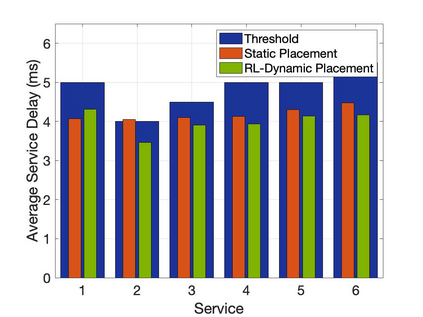
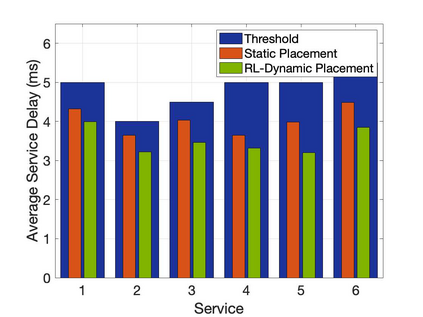
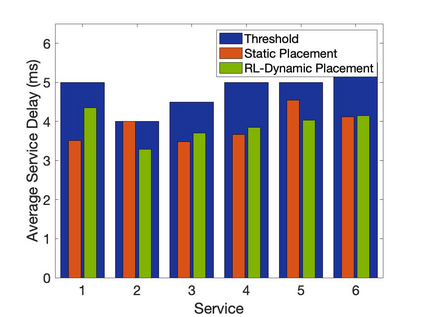
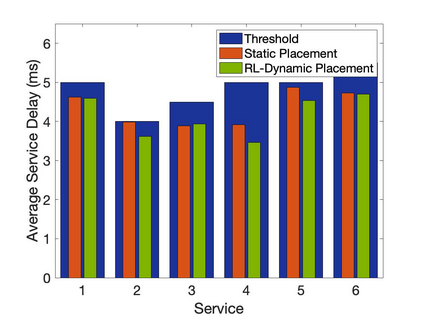
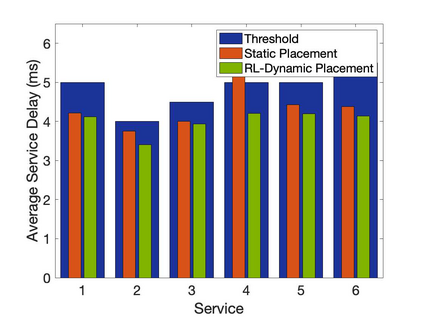
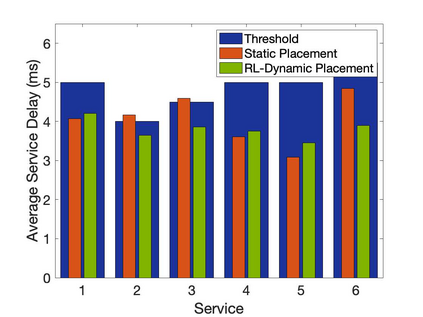
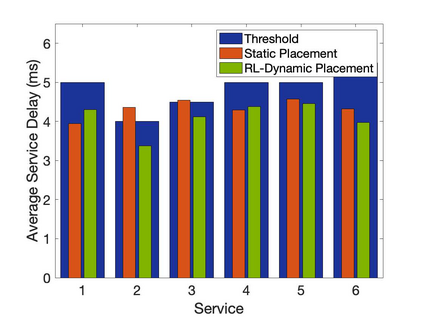
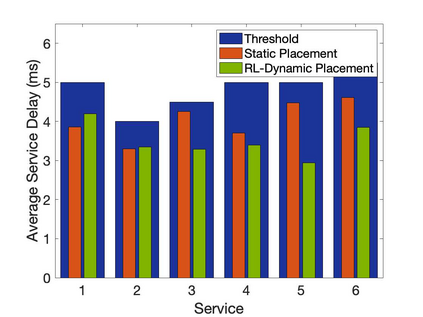
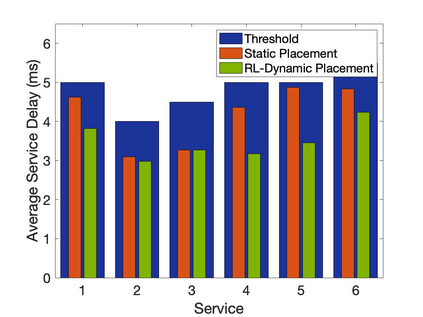
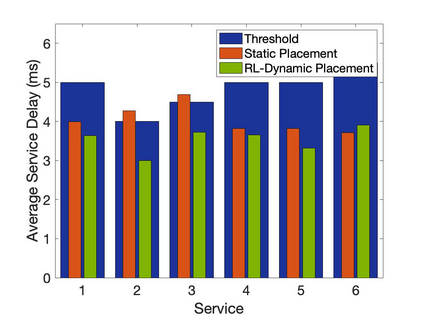
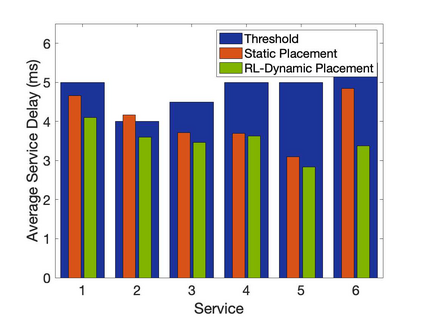
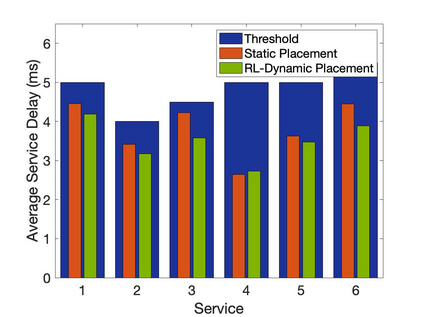
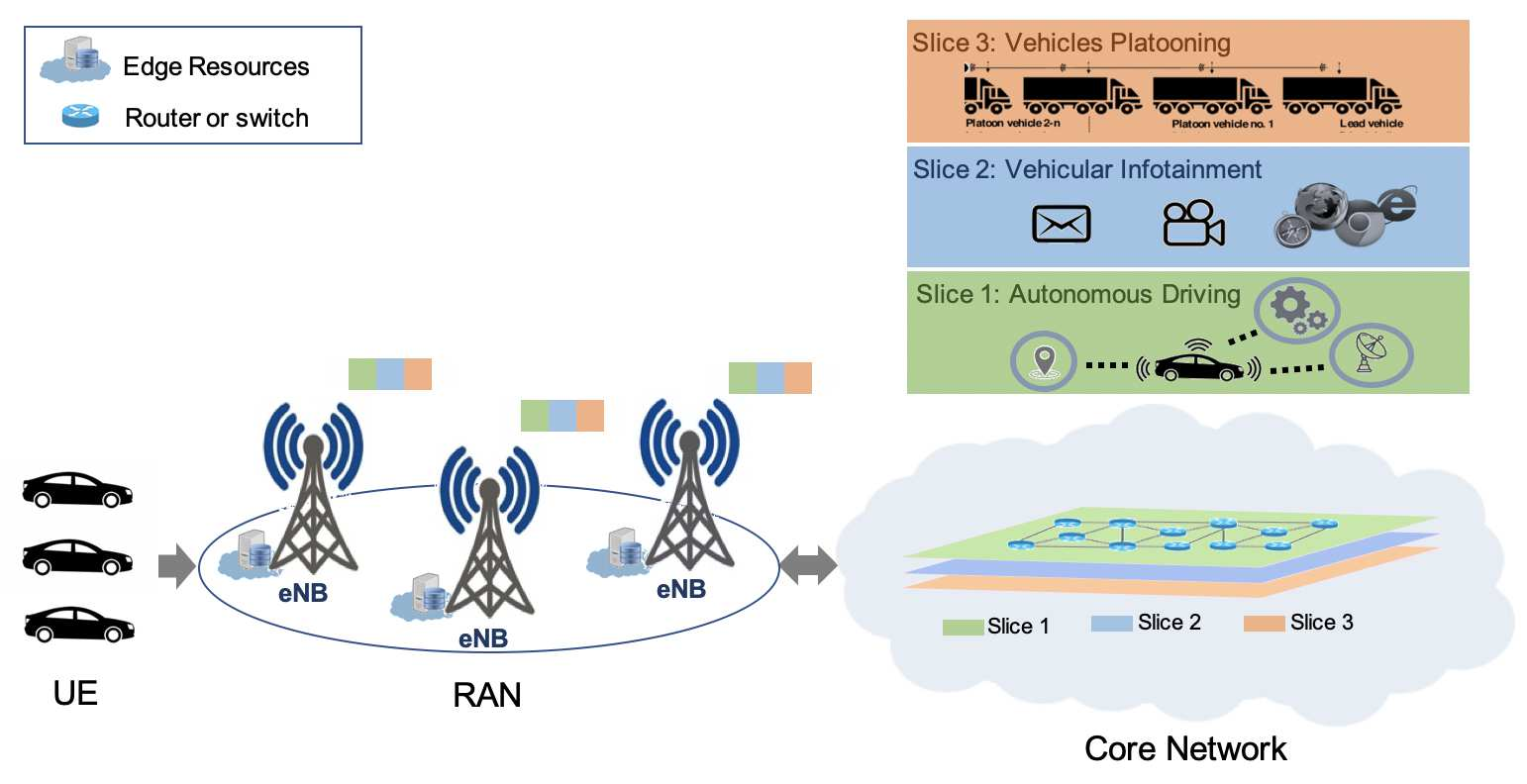
The emergence of technologies such as 5G and mobile edge computing has enabled provisioning of different types of services with different resource and service requirements to the vehicles in a vehicular network.The growing complexity of traffic mobility patterns and dynamics in the requests for different types of services has made service placement a challenging task. A typical static placement solution is not effective as it does not consider the traffic mobility and service dynamics. In this paper, we propose a reinforcement learning-based dynamic (RL-Dynamic) service placement framework to find the optimal placement of services at the edge servers while considering the vehicle's mobility and dynamics in the requests for different types of services. We use SUMO and MATLAB to carry out simulation experiments. In our learning framework, for the decision module, we consider two alternative objective functions-minimizing delay and minimizing edge server utilization. We developed an ILP based problem formulation for the two objective functions. The experimental results show that 1) compared to static service placement, RL-based dynamic service placement achieves fair utilization of edge server resources and low service delay, and 2) compared to delay-optimized placement, server utilization optimized placement utilizes resources more effectively, achieving higher fairness with lower edge-server utilization.
翻译:5G和移动边缘计算等技术的出现使得能够向车辆提供不同类型服务,具有不同资源和服务要求的车辆在车辆网络中提供不同类型的服务。 交通流动模式和不同类型服务请求的动态日益复杂,使得服务安置成为一项具有挑战性的任务。 典型的静态安置解决方案并不有效,因为它不考虑交通流动和服务动态。 在本文件中,我们提议了一个基于学习的强化动态(RL-动态)服务定位框架,以便在边缘服务器找到服务的最佳位置,同时考虑到车辆的流动性和不同类型服务请求中的动态。 我们利用SUMO和MATLAB进行模拟实验。 在我们的学习框架中,我们考虑两种备选目标功能,即尽量减少延迟和尽量减少边缘服务器的使用。我们为两项目标功能开发了基于ILP的问题配置。实验结果表明,与静态服务配置相比,基于RL的动态服务定位实现了对边缘服务器资源的公平利用,服务延迟延迟的延迟,服务器优化配置与更高效地利用资源。