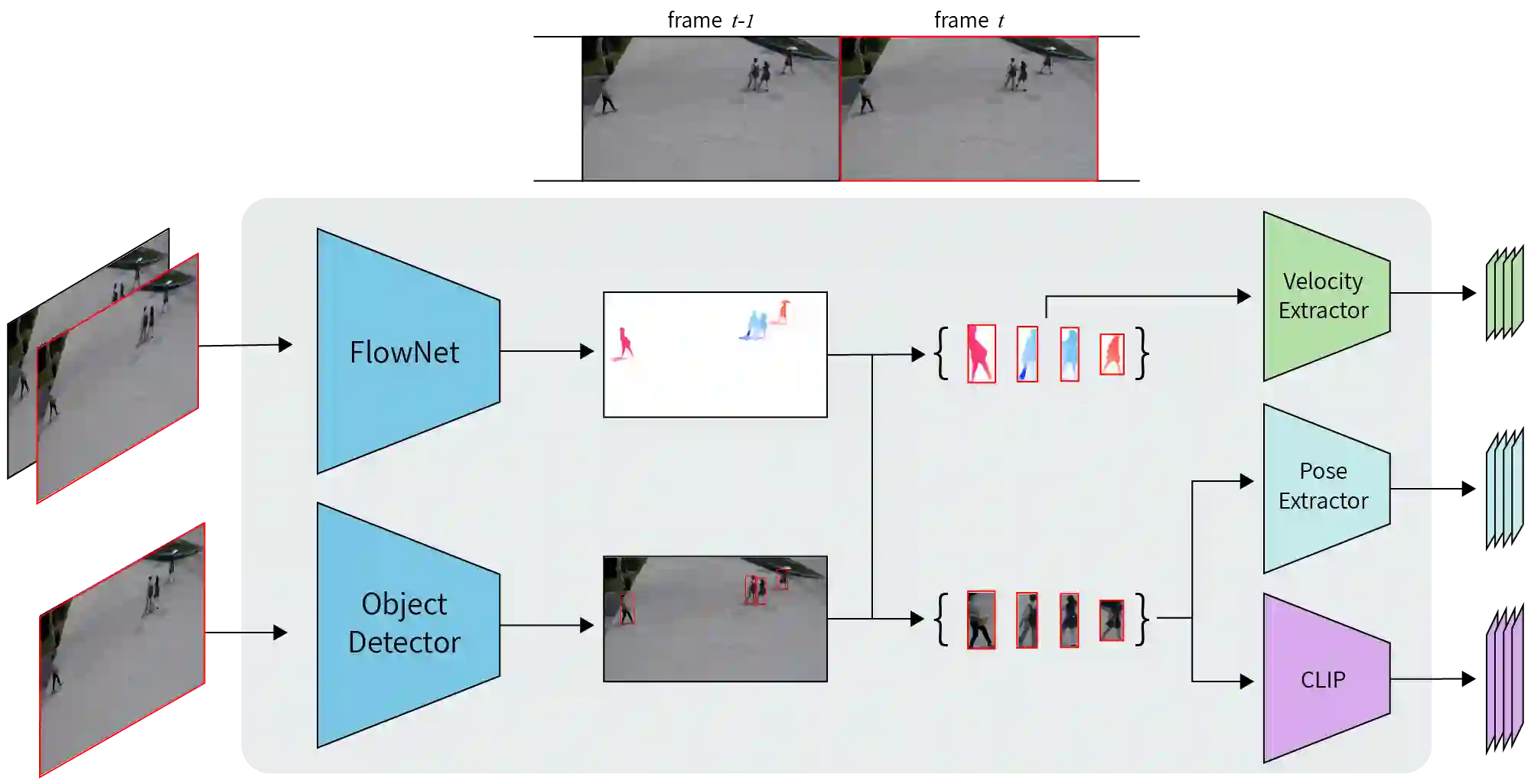
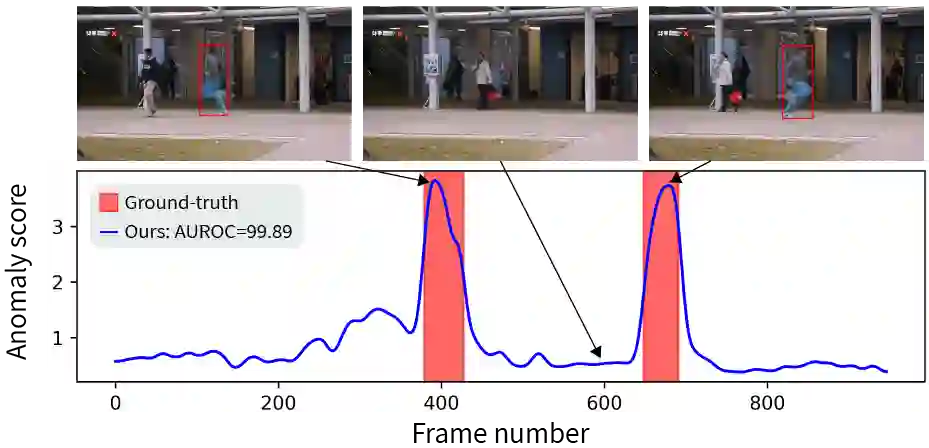
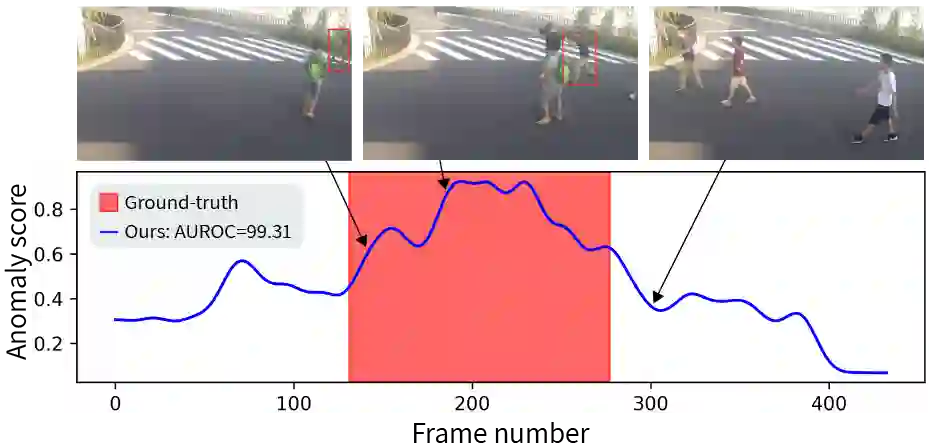
Video anomaly detection (VAD) is a challenging computer vision task with many practical applications. As anomalies are inherently ambiguous, it is essential for users to understand the reasoning behind a system's decision in order to determine if the rationale is sound. In this paper, we propose a simple but highly effective method that pushes the boundaries of VAD accuracy and interpretability using attribute-based representations. Our method represents every object by its velocity and pose. The anomaly scores are computed using a density-based approach. Surprisingly, we find that this simple representation is sufficient to achieve state-of-the-art performance in ShanghaiTech, the largest and most complex VAD dataset. Combining our interpretable attribute-based representations with implicit, deep representation yields state-of-the-art performance with a $99.1\%, 93.3\%$, and $85.9\%$ AUROC on Ped2, Avenue, and ShanghaiTech, respectively. Our method is accurate, interpretable, and easy to implement.
翻译:视频异常探测( VAD) 是一项具有挑战性的计算机视觉任务, 有许多实际应用。 异常现象本质上是模棱两可的, 用户必须理解系统决定背后的推理, 以确定理由是否合理。 在本文中, 我们提出一个简单而高效的方法, 使用基于属性的表达方式推移 VAD 准确性和可解释性的界限。 我们的方法代表着每个对象, 其速度和姿势。 异常分数是用基于密度的方法计算的。 令人惊讶的是, 我们发现这种简单的表达方式足以实现上海科技的最新性能, 上海科技是最大和最复杂的VAD数据集。 将我们可解释的属性表达方式与隐含的、 深层的表达方式结合起来, 产生最先进的表现方式, 在Ped2大道和上海科技分别是99.1 、93.3 和85.9 澳元 AUROC 。 我们的方法准确、 可解释和易于执行。