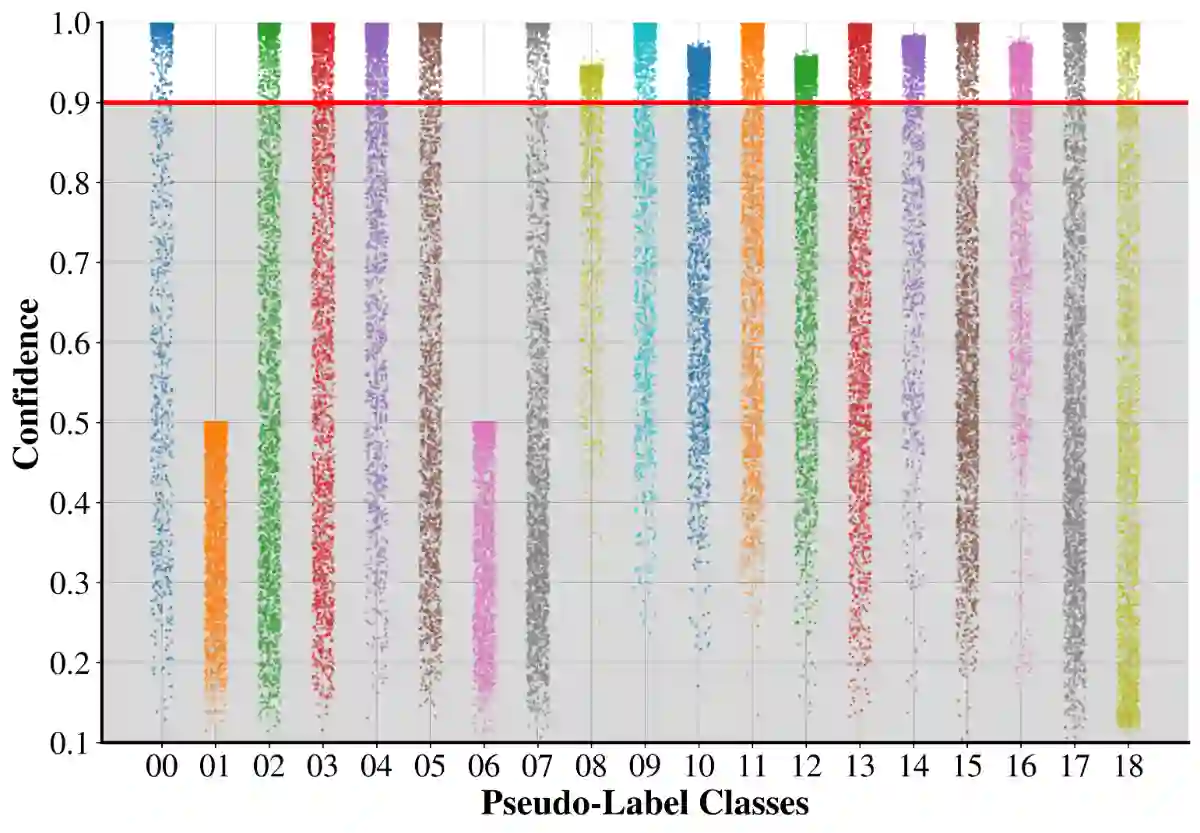
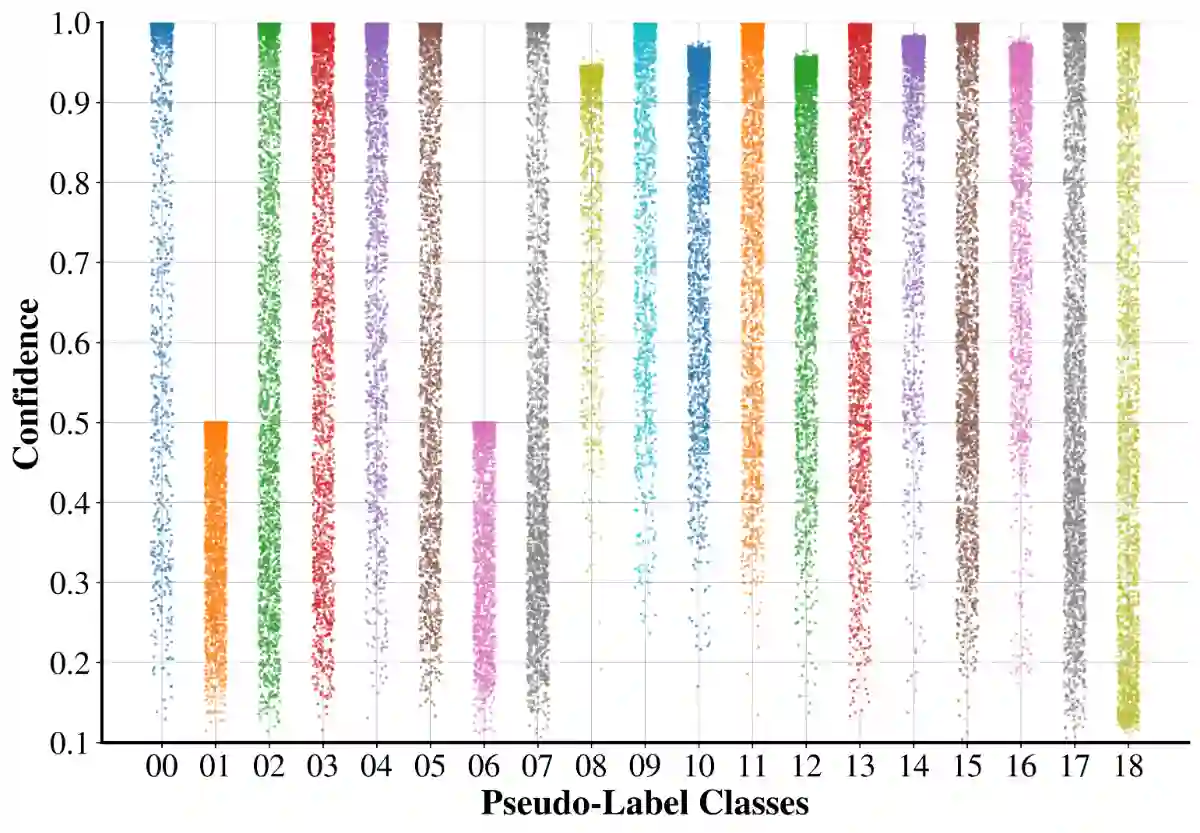
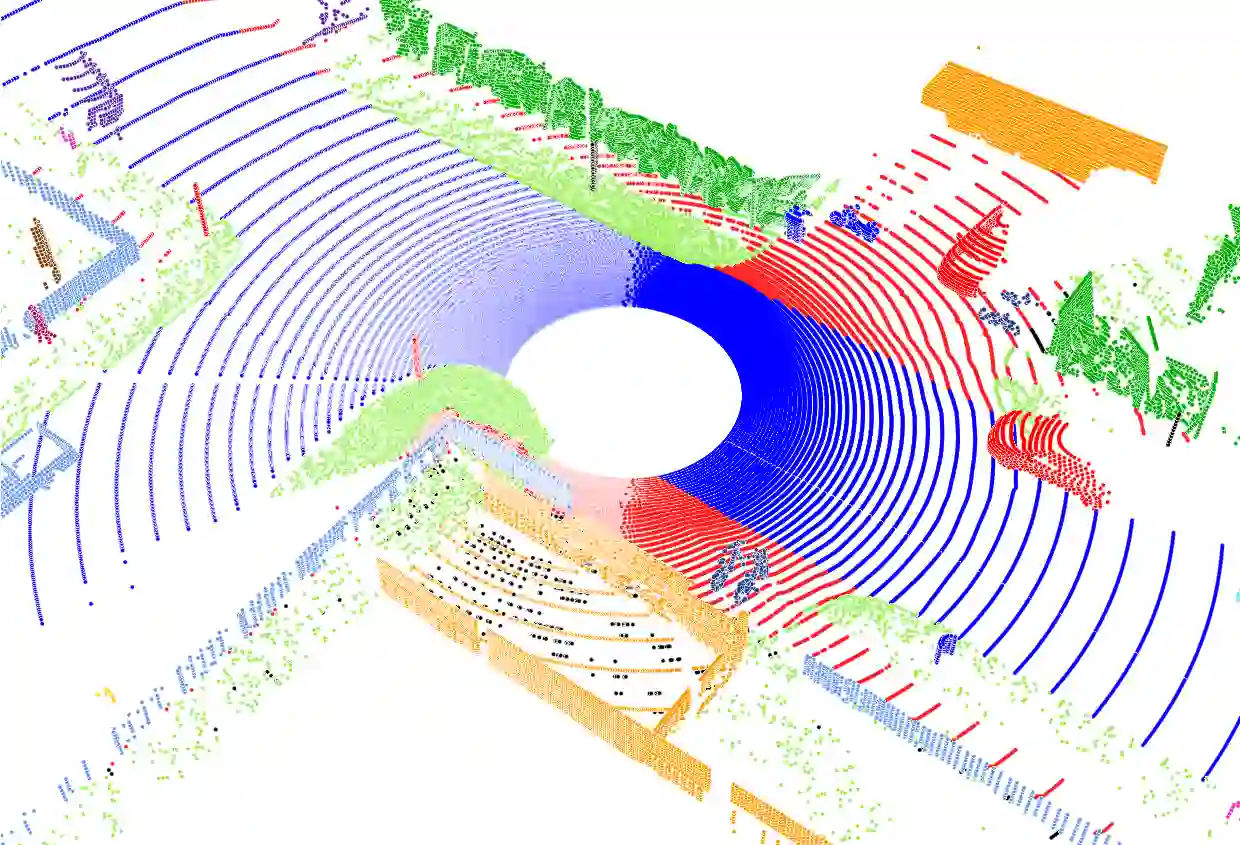
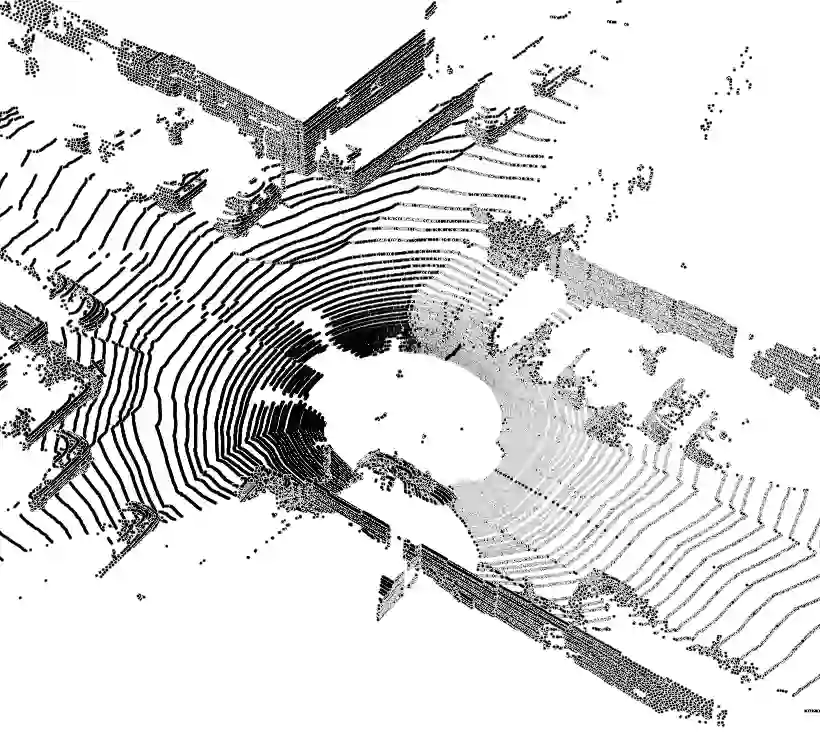
Annotating real-world LiDAR point clouds for use in intelligent autonomous systems is costly. To overcome this limitation, self-training-based Unsupervised Domain Adaptation (UDA) has been widely used to improve point cloud semantic segmentation by leveraging synthetic point cloud data. However, we argue that existing methods do not effectively utilize unlabeled data, as they either rely on predefined or fixed confidence thresholds, resulting in suboptimal performance. In this paper, we propose a Dynamic Pseudo-Label Filtering (DPLF) scheme to enhance real data utilization in point cloud UDA semantic segmentation. Additionally, we design a simple and efficient Prior-Guided Data Augmentation Pipeline (PG-DAP) to mitigate domain shift between synthetic and real-world point clouds. Finally, we utilize data mixing consistency loss to push the model to learn context-free representations. We implement and thoroughly evaluate our approach through extensive comparisons with state-of-the-art methods. Experiments on two challenging synthetic-to-real point cloud semantic segmentation tasks demonstrate that our approach achieves superior performance. Ablation studies confirm the effectiveness of the DPLF and PG-DAP modules. We release the code of our method in this paper.
翻译:为智能自主系统标注真实世界的激光雷达点云成本高昂。为克服这一限制,基于自训练的无监督域自适应方法被广泛用于通过利用合成点云数据来提升点云语义分割性能。然而,我们认为现有方法未能有效利用未标注数据,因为它们要么依赖预定义的置信度阈值,要么采用固定的阈值,导致性能欠佳。本文提出一种动态伪标签过滤方案,以增强点云UDA语义分割中对真实数据的利用。此外,我们设计了一个简单高效的先验引导数据增强流程,以缓解合成点云与真实点云之间的域偏移。最后,我们利用数据混合一致性损失来推动模型学习与上下文无关的表征。我们实现了所提出的方法,并通过与最先进方法的广泛比较进行了全面评估。在两个具有挑战性的合成到真实点云语义分割任务上的实验表明,我们的方法取得了卓越的性能。消融研究证实了DPLF和PG-DAP模块的有效性。我们在本文中公开了方法的代码。