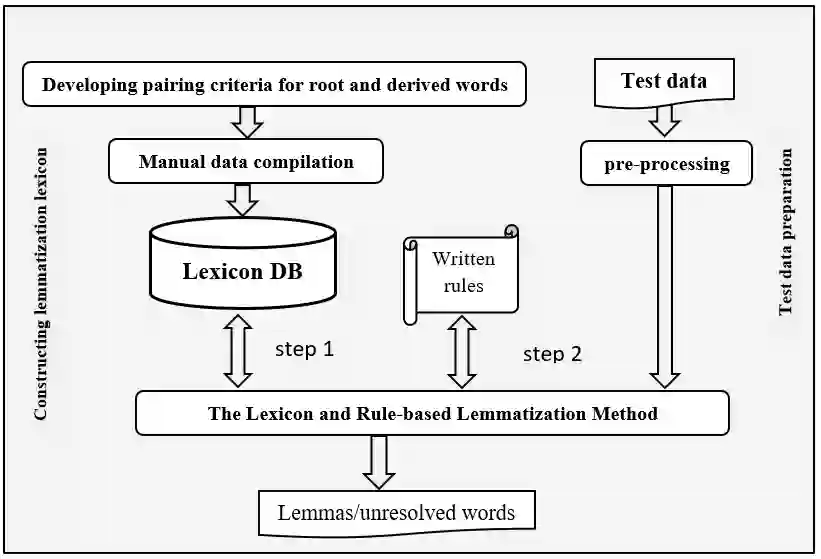
Lemmatization is a Natural Language Processing (NLP) technique used to normalize text by changing morphological derivations of words to their root forms. It is used as a core pre-processing step in many NLP tasks including text indexing, information retrieval, and machine learning for NLP, among others. This paper pioneers the development of text lemmatization for the Somali language, a low-resource language with very limited or no prior effective adoption of NLP methods and datasets. We especially develop a lexicon and rule-based lemmatizer for Somali text, which is a starting point for a full-fledged Somali lemmatization system for various NLP tasks. With consideration of the language morphological rules, we have developed an initial lexicon of 1247 root words and 7173 derivationally related terms enriched with rules for lemmatizing words not present in the lexicon. We have tested the algorithm on 120 documents of various lengths including news articles, social media posts, and text messages. Our initial results demonstrate that the algorithm achieves an accuracy of 57\% for relatively long documents (e.g. full news articles), 60.57\% for news article extracts, and high accuracy of 95.87\% for short texts such as social media messages.
翻译:暂无翻译