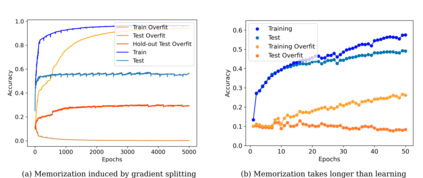
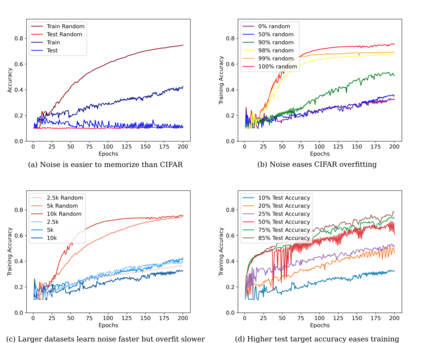
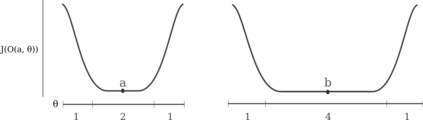
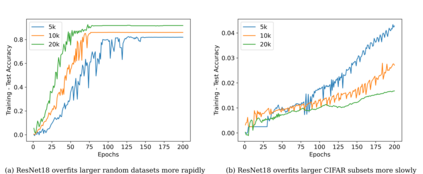
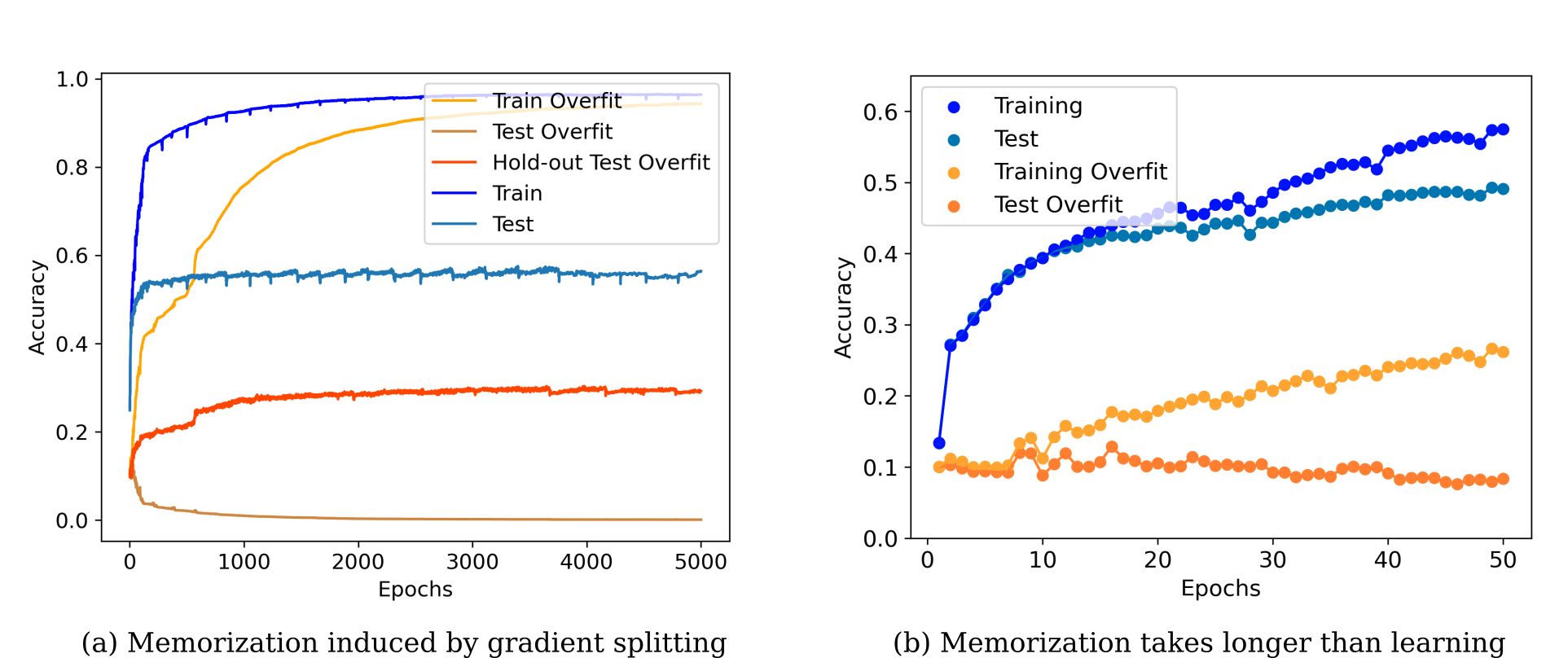
Very large deep learning models trained using gradient descent are remarkably resistant to memorization given their huge capacity, but are at the same time capable of fitting large datasets of pure noise. Here methods are introduced by which models may be trained to memorize datasets that normally are generalized. We find that memorization is difficult relative to generalization, but that adding noise makes memorization easier. Increasing the dataset size exaggerates the characteristics of that dataset: model access to more training samples makes overfitting easier for random data, but somewhat harder for natural images. The bias of deep learning towards generalization is explored theoretically, and we show that generalization results from a model's parameters being attracted to points of maximal stability with respect to that model's inputs during gradient descent.
翻译:使用梯度下移法培训的非常大型的深层学习模型,由于能力巨大,非常耐受记忆化,但同时也能够安装大量纯噪音数据集。这里采用了一些方法,可以对模型进行培训,以便记忆通常普遍化的数据集。我们发现,记忆化相对一般化而言是困难的,但添加噪音则比较容易记忆化。增加数据集的大小夸大了该数据集的特性:获得更多培训样本的模型使随机数据更容易使用,但对自然图像来说则有些困难。深层次学习偏向一般化的倾向在理论上得到探讨,我们表明,模型参数的概括性结果被吸引到该模型在梯度下下降期间投入的最大稳定性点上。