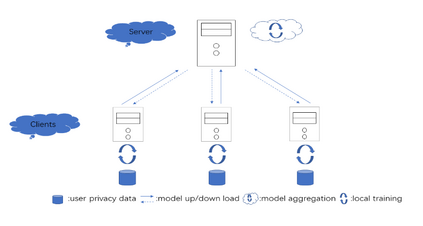
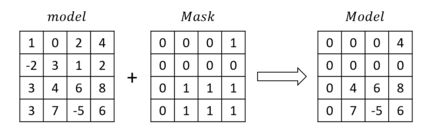
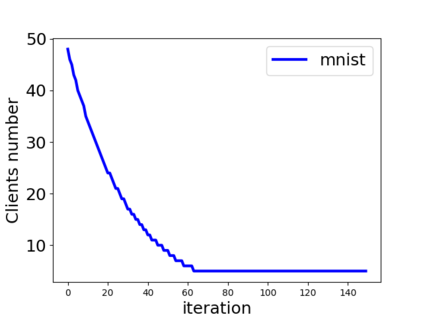
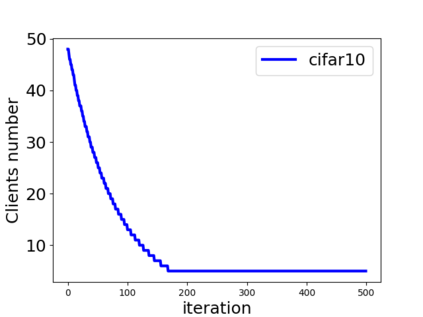
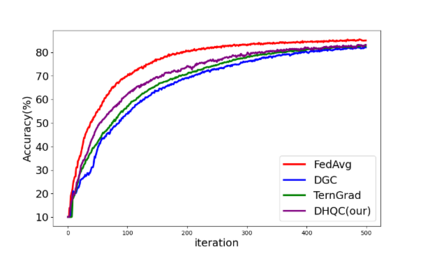
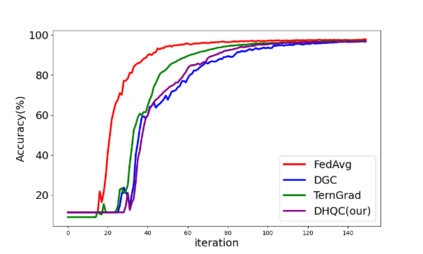
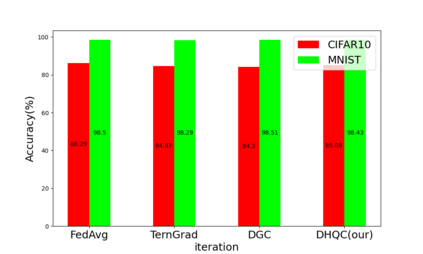
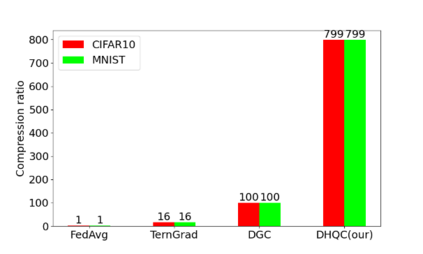
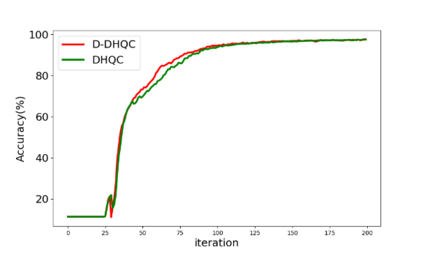
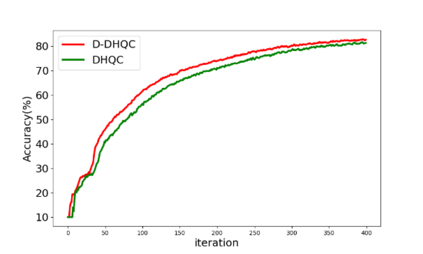
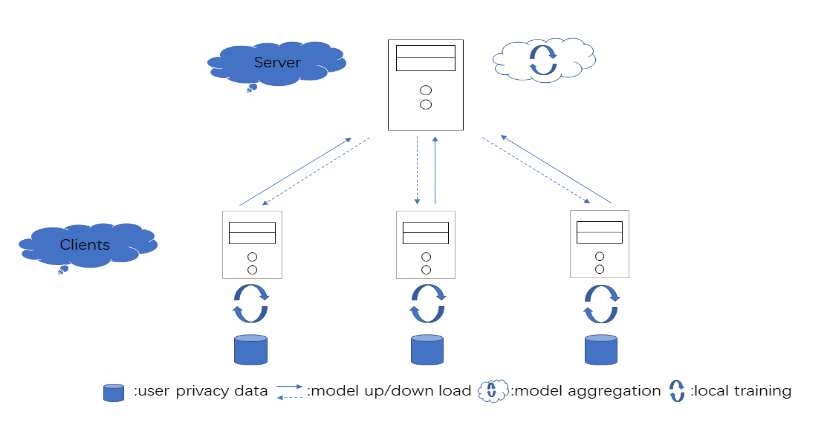
Unlike traditional distributed machine learning, federated learning stores data locally for training and then aggregates the models on the server, which solves the data security problem that may arise in traditional distributed machine learning. However, during the training process, the transmission of model parameters can impose a significant load on the network bandwidth. It has been pointed out that the vast majority of model parameters are redundant during model parameter transmission. In this paper, we explore the data distribution law of selected partial model parameters on this basis, and propose a deep hierarchical quantization compression algorithm, which further compresses the model and reduces the network load brought by data transmission through the hierarchical quantization of model parameters. And we adopt a dynamic sampling strategy for the selection of clients to accelerate the convergence of the model. Experimental results on different public datasets demonstrate the effectiveness of our algorithm.
翻译:与传统的分布式机器学习不同,联合会式学习存储当地的培训数据,然后汇总服务器上的模型,解决传统分布式机器学习中可能出现的数据安全问题。但是,在培训过程中,模型参数的传输可对网络带宽造成相当大的负担。人们已经指出,绝大多数模型参数在模型参数传输期间是多余的。在本文中,我们以此为基础探讨选定部分模型参数的数据分配法,并提出一个深层次的分级压缩算法,进一步压缩模型,并通过模型参数的等级化化来减少数据传输带来的网络负荷。我们还采用了动态抽样战略,选择客户以加速模型的趋同。不同公共数据集的实验结果显示了我们的算法的有效性。