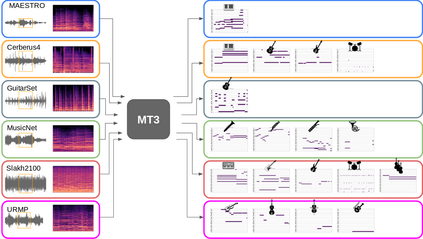
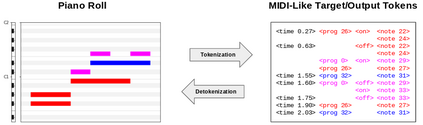
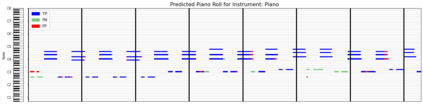
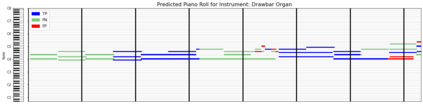
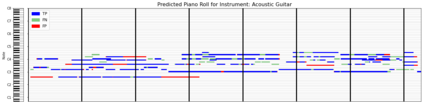
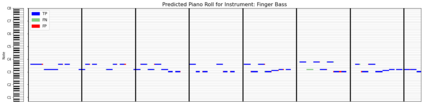
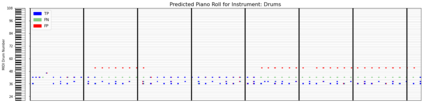
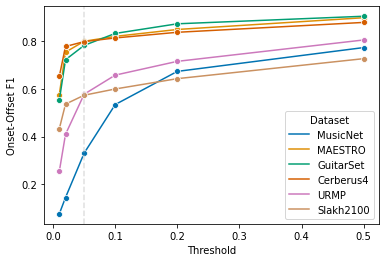
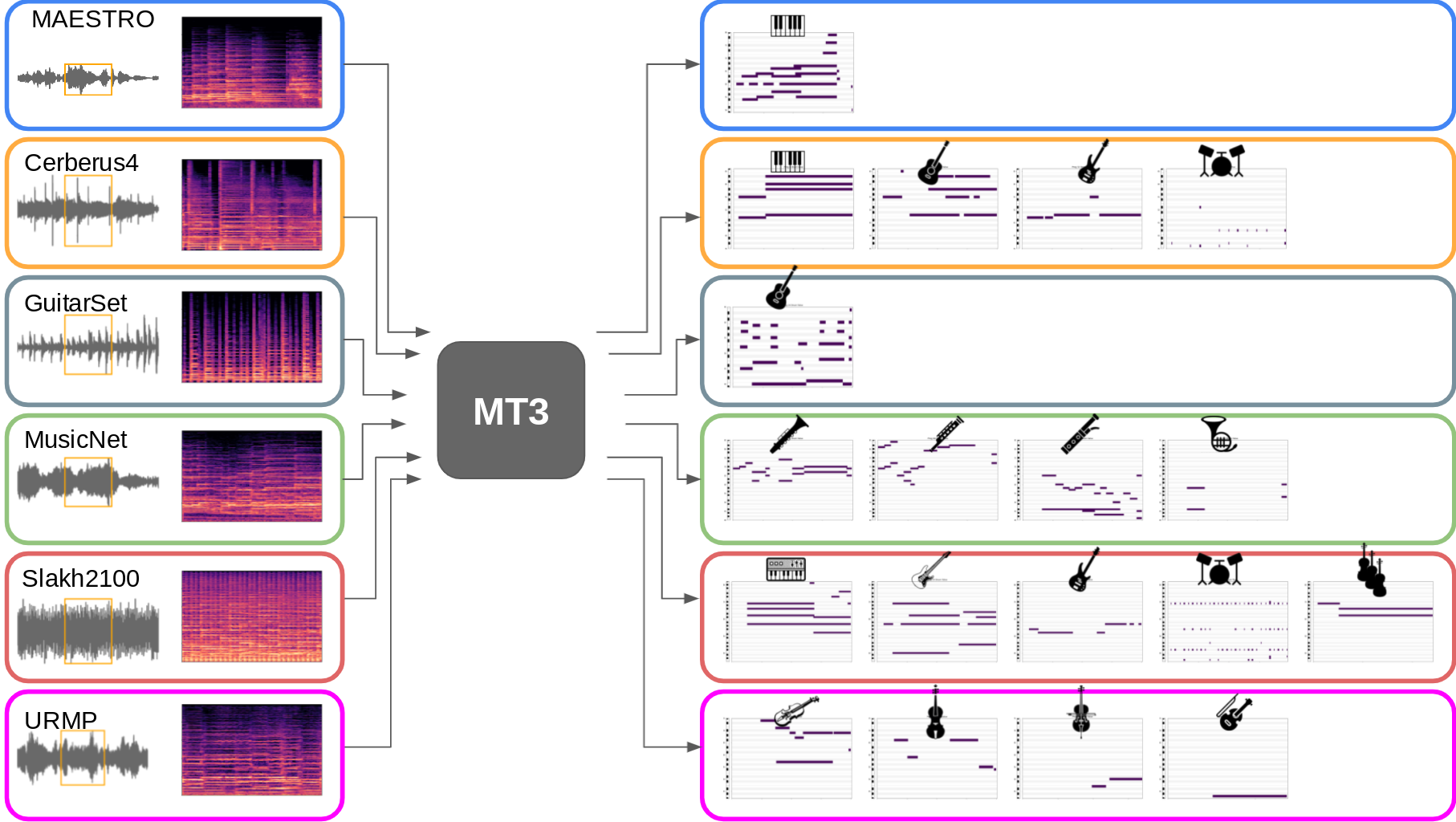
Automatic Music Transcription (AMT), inferring musical notes from raw audio, is a challenging task at the core of music understanding. Unlike Automatic Speech Recognition (ASR), which typically focuses on the words of a single speaker, AMT often requires transcribing multiple instruments simultaneously, all while preserving fine-scale pitch and timing information. Further, many AMT datasets are "low-resource", as even expert musicians find music transcription difficult and time-consuming. Thus, prior work has focused on task-specific architectures, tailored to the individual instruments of each task. In this work, motivated by the promising results of sequence-to-sequence transfer learning for low-resource Natural Language Processing (NLP), we demonstrate that a general-purpose Transformer model can perform multi-task AMT, jointly transcribing arbitrary combinations of musical instruments across several transcription datasets. We show this unified training framework achieves high-quality transcription results across a range of datasets, dramatically improving performance for low-resource instruments (such as guitar), while preserving strong performance for abundant instruments (such as piano). Finally, by expanding the scope of AMT, we expose the need for more consistent evaluation metrics and better dataset alignment, and provide a strong baseline for this new direction of multi-task AMT.
翻译:从原始音频中推断出音乐笔记(AMT)的自动音乐记录(AMT)是音乐理解的核心,是一项具有挑战性的任务。与通常侧重于单一发言者的单词的自动语音识别(ASR)不同,AMT通常要求同时翻译多种工具,同时保存精细的音调和时间信息。此外,许多AMT数据集“资源较低 ”, 因为即使是专业音乐家也发现音乐笔录困难和耗时。因此,先前的工作侧重于根据每项任务的具体工具定制的任务特定结构。在这项工作中,由于低资源自然语言处理的顺序到顺序转移学习(NLP)的有希望的结果,我们证明通用的变换模型可以同时进行多功能的AMT,共同将音乐工具任意结合到数个曲调数据集中。我们展示了这个统一的培训框架在一系列数据集中取得了高质量的抄录结果,大大改进了低资源工具(例如吉他)的性能,同时保持大量仪器(例如钢琴)的强劲性能。最后,我们证明一个通用的变换模型模型模式可以执行多功能,联合翻译和多功能的基线,我们需要更紧密的AMTAMTA的新的数据。