
ACM Multimedia 2021于10月20日至24日在中国成都举办,20日主要日程为Workshop和Tutorial。
多媒体分析研究近年来取得了长足进展,相关技术在单项测试中的准确率达到甚至超过了人类水平,正逐步实现从“不能用”到“可以用”的技术跨越。然而,在医疗诊断、无人驾驶等强安全相关的应用领域,由于鲁棒性差、违背常识伦理、无法测试调试等问题,距离“很好用”仍有一段距离。10月20日下午北京交通大学组织了"可信赖多媒体分析"的Tutorial,探讨多媒体分析从"可以用"到"很好用"的技术解决方案。Tutorial共分为四个部分:
- 可信赖多媒体分析:知识蒸馏中的两种虚假相关性
- 准确性兼容的公平性计算
- 良性对抗攻击:对抗隐私保护
- 可信赖用户建模:解释性、鲁棒性、公平性、隐私和安全性
报告内容
Trustworthy Multimedia Analysis: the Two Types of Spurious Correlations in Distilling Human Knowledge
可信赖多媒体分析:知识蒸馏中的两种虚假相关性
报告人:桑基韬
http://faculty.bjtu.edu.cn/9129/
从引入人类知识中获得的两种虚假关联开始,我们沿着任务相关和语义两个维度划分(视觉)特征空间。可信多媒体分析理论上依赖于与任务相关的语义特征,由训练、可解释和测试三个模块组成。这三个模块基本上构成了一个闭环,分别处理提取任务相关特征、提取任务相关语义特征,纠正虚假相关目标。
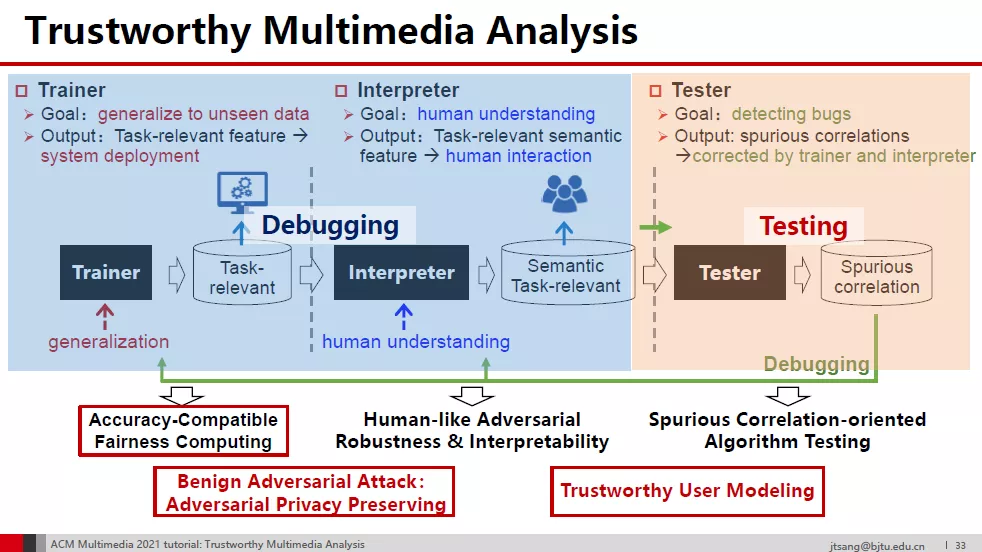
Accuracy-compatible Fairness Computing in Multimedia
准确性兼容的公平性计算
报告人:张翼
多年来,多媒体计算研究主要在关注算法的准确性,期待算法能够拥有人类水平的多媒体理解能力。近年来,随着以深度学习为代表的技术突破,算法已经表现出超越人类的准确率,比如在图像识别和阅读理解等任务中。然而,随着算法在真实世界的大规模部署,也暴露出了算法存在歧视和偏见的潜在问题,越来越多的研究者开始关注算法的公平性问题。本报告以消除图像识别中的算法不公平为例,基于算法偏见的来源提出两个方法消除图像识别中的算法偏见,并且兼容了算法准确性。具体的,我们从训练和测试的角度出发,分别消除数据和模型中对任务不相关特征的依赖,而不改变对任务相关特征的依赖。因此在保证模型准确性的同时,实现了算法公平。
Benign Adversarial Attack: Adversarial Privacy-preserving
良性对抗攻击:对抗隐私保护
报告人:张家明
关于对抗样本的研究近些年成为了学界中的热点,围绕着对抗样本的对抗攻击(Adversarial attack)和对抗防御(Adversarial defense)也层出不穷。然而,目前学界的主流理解还是将其视为人工智能算法的一个漏洞,并试图解决它。本报告从另一个角度出发,不再将对抗样本当作一个漏洞,而是剖析了它的三个特点:可以被作为算法的特征(Utilizable as feature)、只会对算法产生影响(Exclusive to algorithm)、算法对其十分敏感(Inevitable for vulnerability)。本报告根据对抗样本的以上三个特点,介绍并讨论了三种良性的应用场景:对抗数据增强(Adversarial data augmentation)、对抗图灵测试(Adversarial Turing Test)、隐私保护(Privacy-preserving)。
Trustworthy User Modeling
可信赖用户建模
报告人:黄晓雯
http://faculty.bjtu.edu.cn/9545/
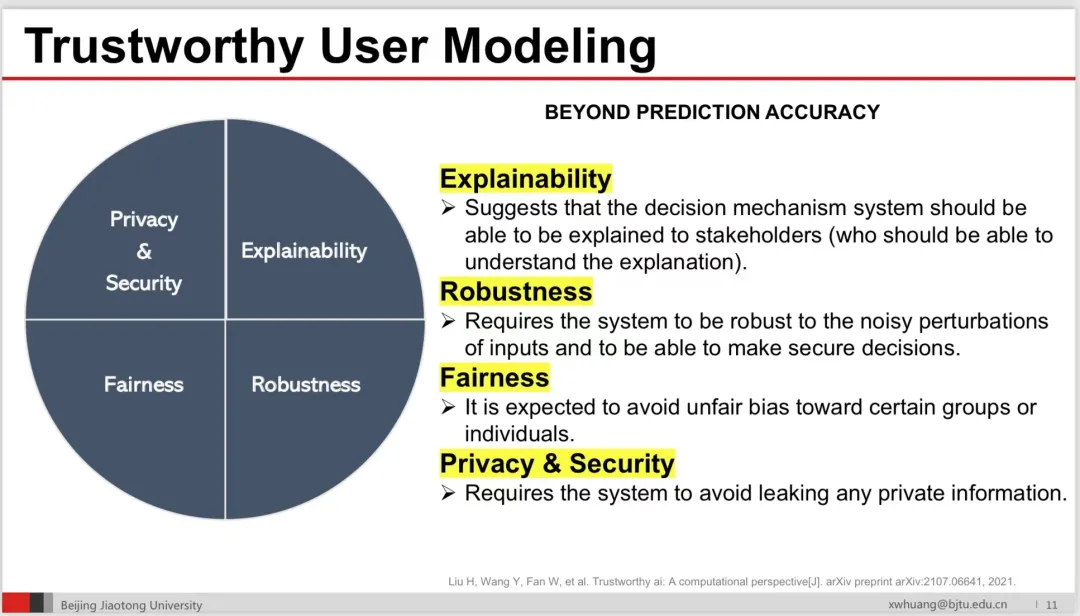
用户在社会媒体中的角色既是内容的生产者,又是社会媒体服务的终极目标。个性化服务需要了解用户的喜好和兴趣,就需要从用户的网络平台行为数据中分析和理解用户,进行用户建模,推测用户的未知属性或兴趣。用户建模具有极高的应用价值,如:多媒体检索、推荐系统、精准营销和各式各样的个性化服务等。本报告以推荐系统这一下游应用为例,介绍可信赖用户建模。多年来,推荐系统主要关注系统效益(Effectiveness)、效率(Efficiency)、全面性(Sufficiency)和多样性(Diversity)等方面。随着可信赖人工智能的发展,可信赖用户建模强调关注解释性(Explainability)、鲁棒性(Robustness)、公平性(Fairness)、隐私和安全性(Privacy and Security)。本报告介绍了上述四个方面的相关定义、研究进展、评估方式和未来工作。
本次tutorial slides下载地址:
成为VIP会员查看完整内容
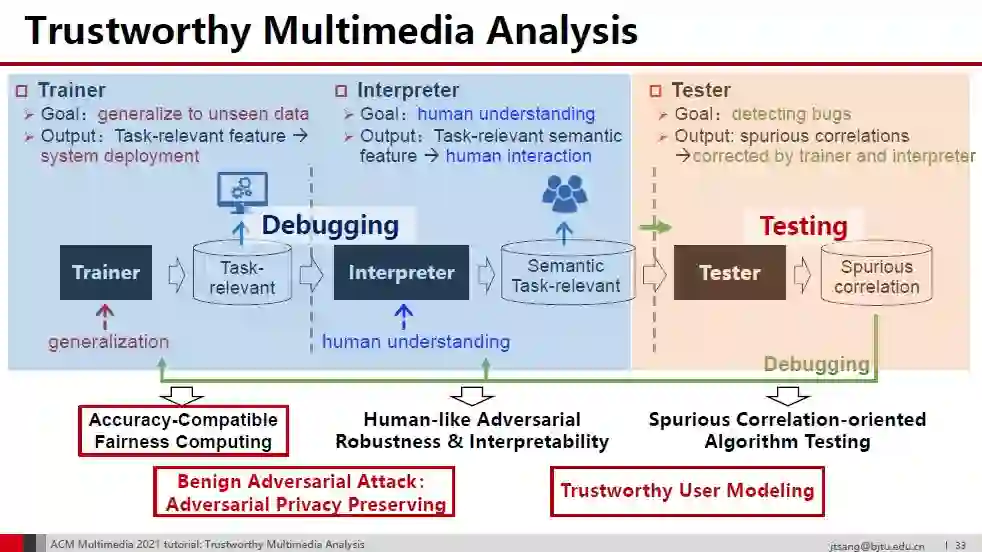
相关内容
Arxiv
0+阅读 · 2021年12月10日
相关主题


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年12月10日