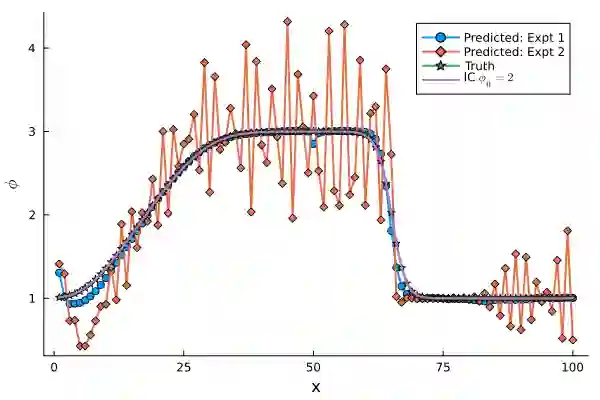
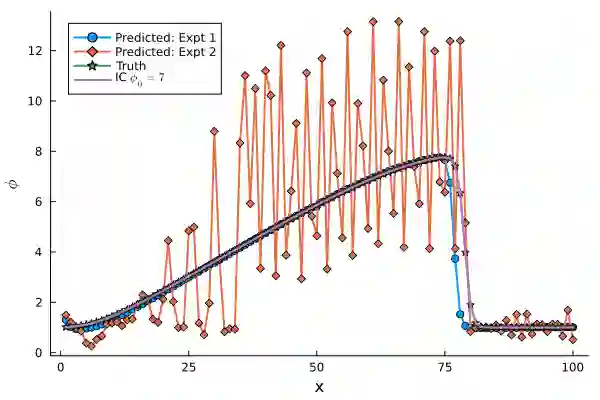
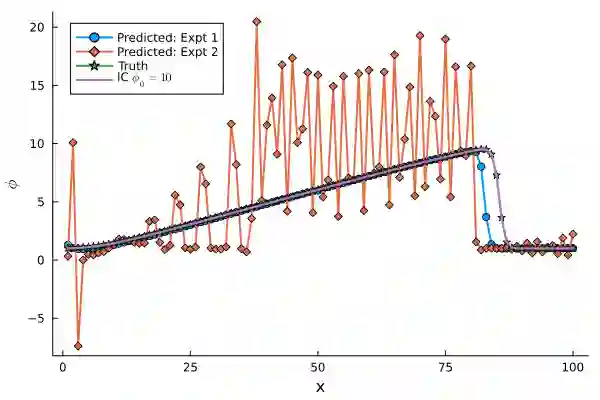
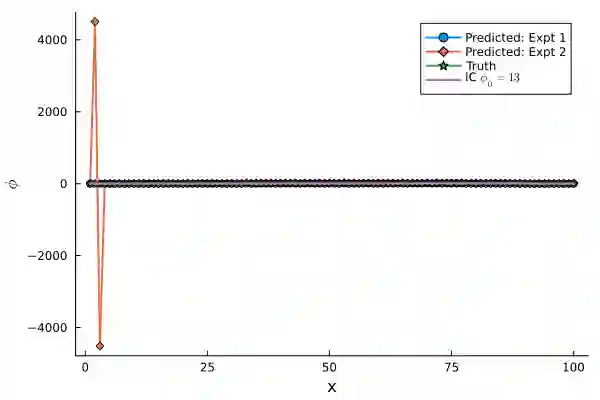
Differentiable Programming for scientific machine learning (SciML) has recently seen considerable interest and success, as it directly embeds neural networks inside PDEs, often called as NeuralPDEs, derived from first principle physics. Therefore, there is a widespread assumption in the community that NeuralPDEs are more trustworthy and generalizable than black box models. However, like any SciML model, differentiable programming relies predominantly on high-quality PDE simulations as "ground truth" for training. However, mathematics dictates that these are only discrete numerical approximations of the true physics. Therefore, we ask: Are NeuralPDEs and differentiable programming models trained on PDE simulations as physically interpretable as we think? In this work, we rigorously attempt to answer these questions, using established ideas from numerical analysis, experiments, and analysis of model Jacobians. Our study shows that NeuralPDEs learn the artifacts in the simulation training data arising from the discretized Taylor Series truncation error of the spatial derivatives. Additionally, NeuralPDE models are systematically biased, and their generalization capability is likely enabled by a fortuitous interplay of numerical dissipation and truncation error in the training dataset and NeuralPDE, which seldom happens in practical applications. This bias manifests aggressively even in relatively accessible 1-D equations, raising concerns about the veracity of differentiable programming on complex, high-dimensional, real-world PDEs, and in dataset integrity of foundation models. Further, we observe that the initial condition constrains the truncation error in initial-value problems in PDEs, thereby exerting limitations to extrapolation. Finally, we demonstrate that an eigenanalysis of model weights can indicate a priori if the model will be inaccurate for out-of-distribution testing.
翻译:暂无翻译