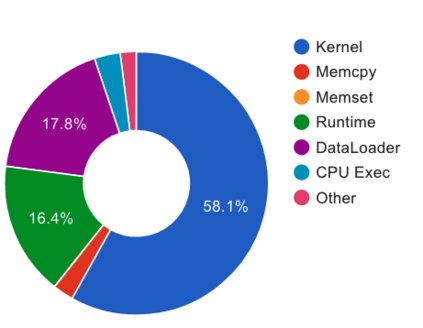
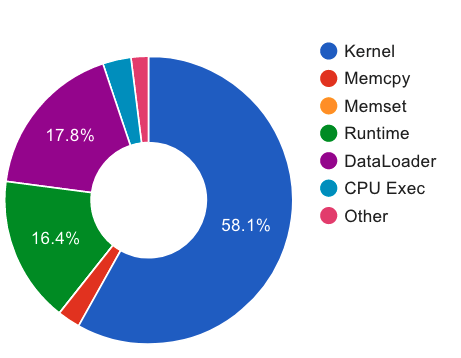
When training neural rankers using Large Language Models, it's expected that a practitioner would make use of multiple GPUs to accelerate the training time. By using more devices, deep learning frameworks, like PyTorch, allow the user to drastically increase the available VRAM pool, making larger batches possible when training, therefore shrinking training time. At the same time, one of the most critical processes, that is generally overlooked when running data-hungry models, is how data is managed between disk, main memory and VRAM. Most open source research implementations overlook this memory hierarchy, and instead resort to loading all documents from disk to main memory and then allowing the framework (e.g., PyTorch) to handle moving data into VRAM. Therefore, with the increasing sizes of datasets dedicated to IR research, a natural question arises: s this the optimal solution for optimizing training time? We here study how three different popular approaches to handling documents for IR datasets behave and how they scale with multiple GPUs. Namely, loading documents directly into memory, reading documents directly from text files with a lookup table and using a library for handling IR datasets (ir_datasets) differ, both in performance (i.e. samples processed per second) and memory footprint. We show that, when using the most popular libraries for neural ranker research (i.e. PyTorch and Hugging Face's Transformers), the practice of loading all documents into main memory is not always the fastest option and is not feasible for setups with more than a couple GPUs. Meanwhile, a good implementation of data streaming from disk can be faster, while being considerably more scalable. We also show how popular techniques for improving loading times, like memory pining, multiple workers, and RAMDISK usage, can reduce the training time further with minor memory overhead.
翻译:当培训使用大语言模型的神经排行器时,人们预计执业者会使用多个 GPU 来加速培训时间。 通过使用更多的设备, 深层次学习框架( 如 PyTorrch ) 使用户能够大幅增加可用的 VRAM 库, 使培训时能够进行更多的批量, 从而缩小培训时间。 同时, 最关键的过程之一, 通常在运行数据饥饿模型时被忽略, 是如何管理磁盘、 主内存和 VRAM 之间的数据。 多数开放源研究的实施会忽略这个记忆等级, 而不是使用从磁盘到主内存的所有文件, 然后让框架( 例如, PyTorrch ) 来处理 VRAM 数据。 因此, 随着专门用于IR 研究的数据集规模越来越大, 一个自然问题出现: 这是优化培训时间的最佳解决方案之一 。 我们在这里研究如何用两种不同的流行的方法来处理 IR 数据集的行为, 以及它们如何与多个 GPUSU 相比, 直接装入记忆, 直接读文件, 直接阅读从文本文件, 以查看表到主内存文件, 选择 选项选项选项选项选项选择 GOD 和 运行 运行 运行 。 我们在运行中, 运行时, 将 运行 运行 运行 运行 数据 数据 运行 运行 运行 的 数据 时间 运行中, 运行中, 运行中, 运行中 。