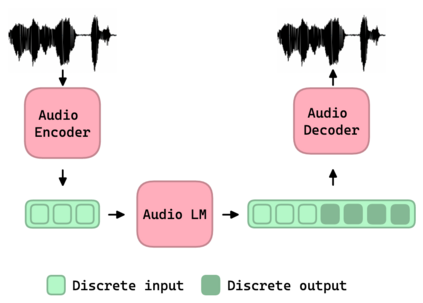
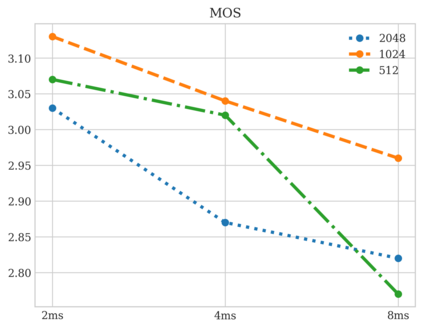
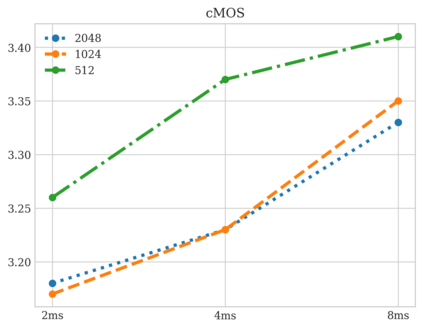
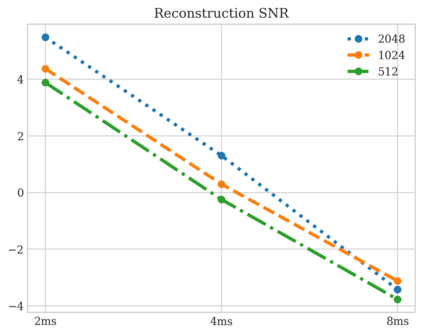
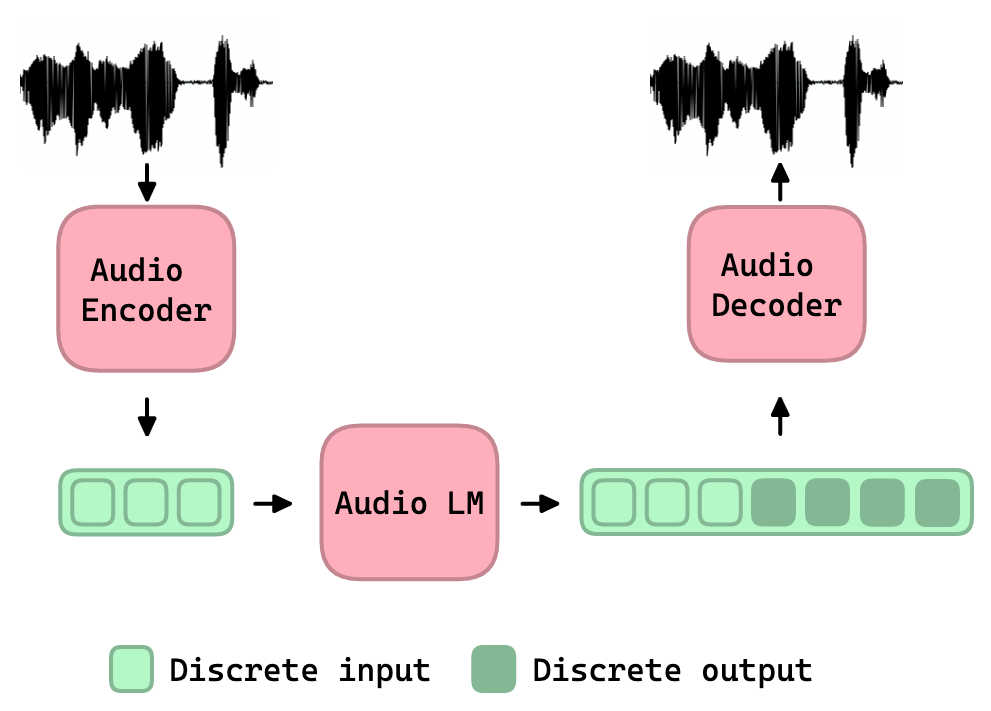
In this work, we study the task of Audio Language Modeling, in which we aim at learning probabilistic models for audio that can be used for generation and completion. We use a state-of-the-art perceptually-guided audio compression model, to encode audio to discrete representations. Next, we train a transformer-based causal language model using these representations. At inference time, we perform audio auto-completion by encoding an audio prompt as a discrete sequence, feeding it to the audio language model, sampling from the model, and synthesizing the corresponding time-domain signal. We evaluate the quality of samples generated by our method on Audioset, the largest dataset for general audio to date, and show that it is superior to the evaluated baseline audio encoders. We additionally provide an extensive analysis to better understand the trade-off between audio-quality and language-modeling capabilities. Samples:link.
翻译:在这项工作中,我们研究音频语言建模的任务,我们的目标是学习可用于生成和完成的音频的概率模型。我们使用最先进的感知制导音频压缩模型,将音频编码为离散的表示方式。接下来,我们用这些表示方式培训一个基于变压器的因果语言模型。推论时间,我们通过将音频提示编码成一个离散序列,将音频自动完成到音频模型,从模型中提取样本,并合成相应的时空域信号。我们评估了我们迄今在音频最大数据集“音频集”上生成的样品的质量,并表明它优于经过评估的基线音频编码器。我们还提供了广泛的分析,以更好地了解音质和语言建模能力之间的权衡。样本:链接。