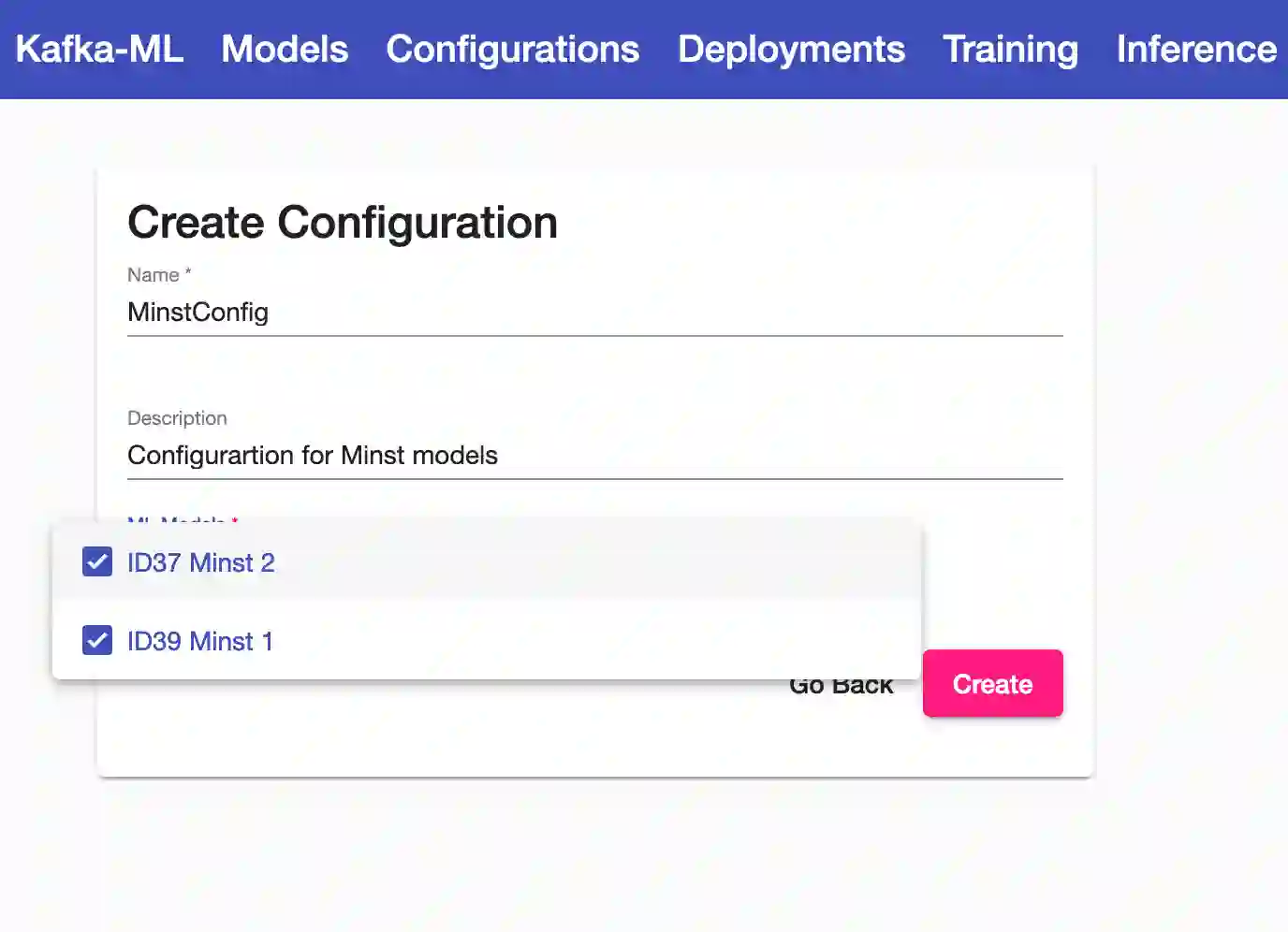
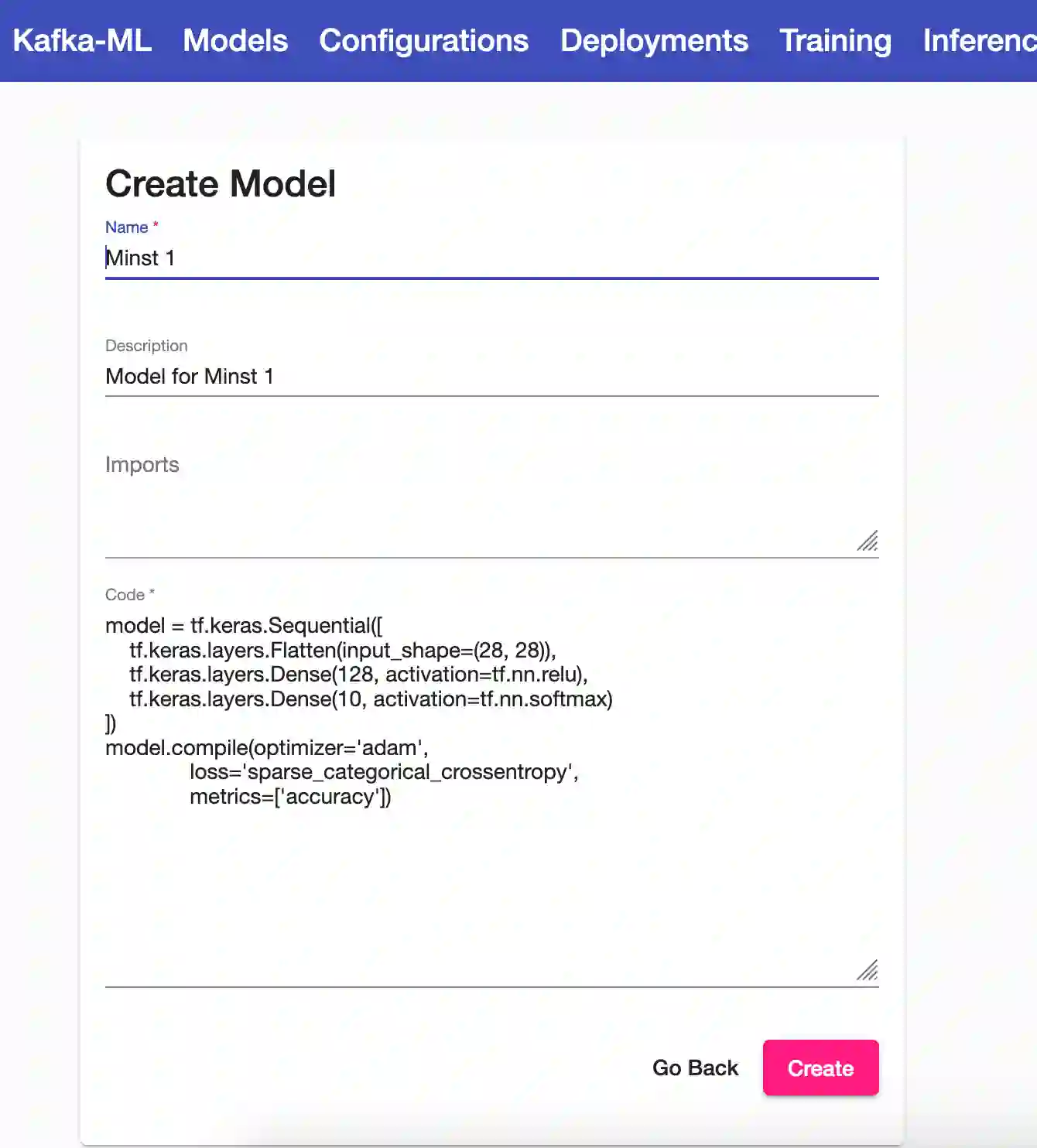
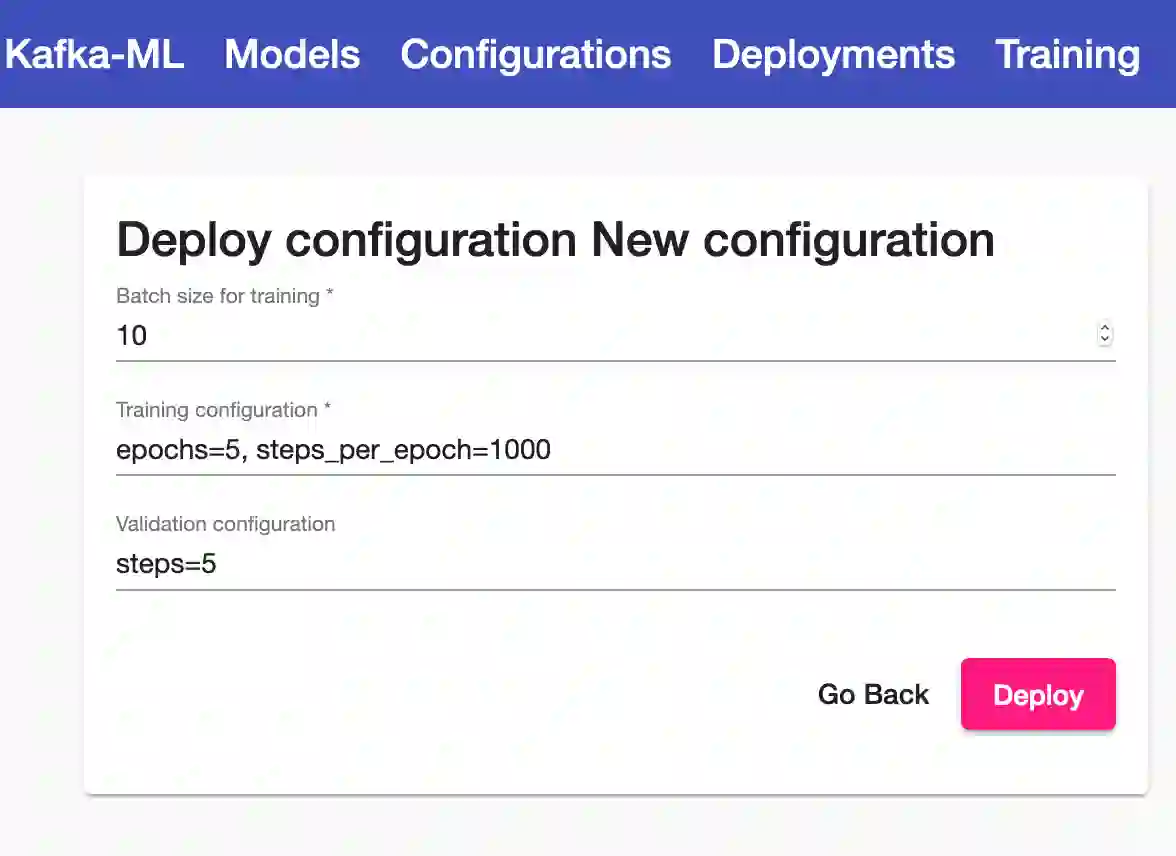
Machine Learning (ML) and Artificial Intelligence (AI) have a dependency on data sources to train, improve and make predictions through their algorithms. With the digital revolution and current paradigms like the Internet of Things, this information is turning from static data into continuous data streams. However, most of the ML/AI frameworks used nowadays are not fully prepared for this revolution. In this paper, we proposed Kafka-ML, an open-source framework that enables the management of TensorFlow ML/AI pipelines through data streams (Apache Kafka). Kafka-ML provides an accessible and user-friendly Web UI where users can easily define ML models, to then train, evaluate and deploy them for inference. Kafka-ML itself and its deployed components are fully managed through containerization technologies, which ensure its portability and easy distribution and other features such as fault-tolerance and high availability. Finally, a novel approach has been introduced to manage and reuse data streams, which may lead to the (no) utilization of data storage and file systems.
翻译:机器学习(ML)和人工智能(AI)依靠数据来源来培训、改进和通过算法作出预测。随着数字革命和诸如Things Internet等当前模式,这种信息正在从静态数据转变为连续的数据流,然而,目前使用的ML/AI框架大多没有为这场革命做好充分准备。在本文件中,我们提出了Kafka-ML,这是一个开放源码框架,能够通过数据流管理TensorFlow ML/AI管道(Apache Kafka)。Kafka-ML提供了一个方便用户的网络界面,用户可以方便地定义ML模型,然后训练、评价和部署这些模型,以便推断。Kafka-ML本身及其部署的部件通过集装箱化技术充分管理,这些技术确保其可移动性和易于分发,以及其他特征,例如过错容忍性和高可用性。最后,我们采用了一种新的办法来管理和再利用数据流,这可能导致数据储存和档案系统的(不)利用。