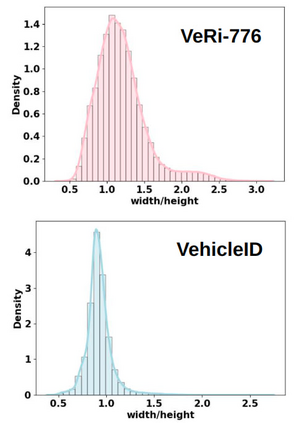
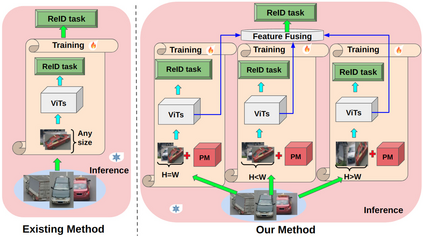
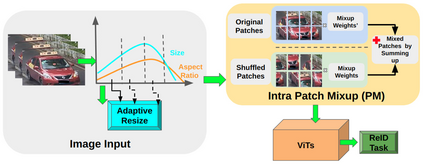
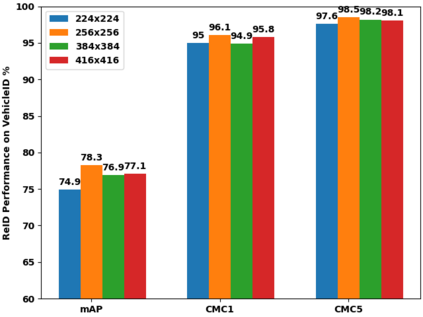
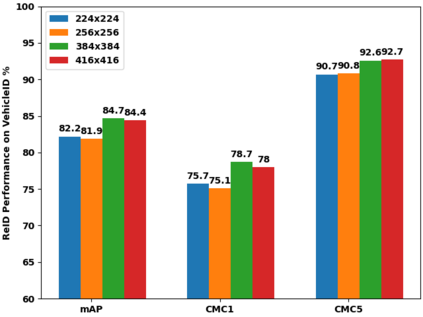
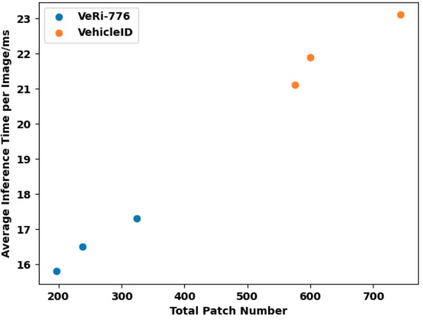
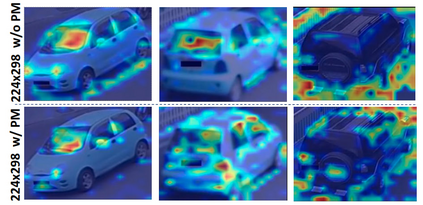
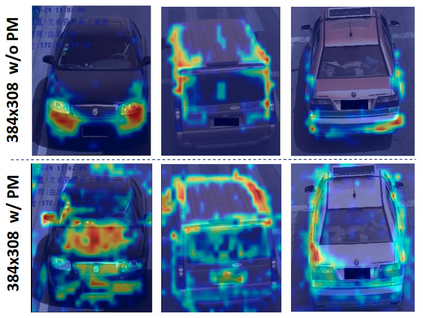
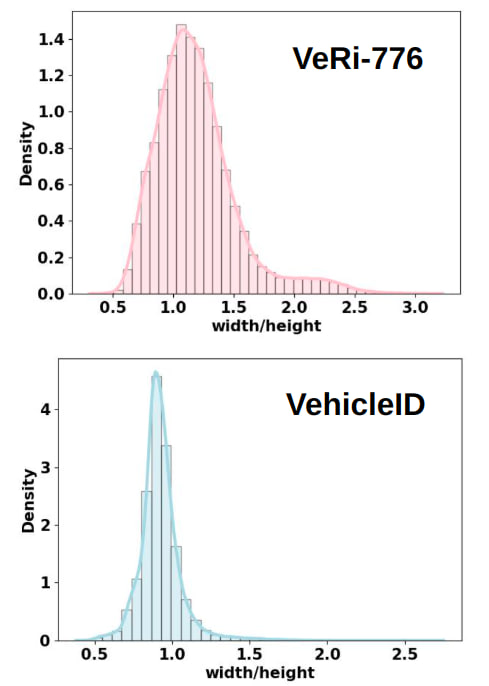
Vision Transformers (ViTs) have excelled in vehicle re-identification (ReID) tasks. However, non-square aspect ratios of image or video input might significantly affect the re-identification performance. To address this issue, we propose a novel ViT-based ReID framework in this paper, which fuses models trained on a variety of aspect ratios. Our main contributions are threefold: (i) We analyze aspect ratio performance on VeRi-776 and VehicleID datasets, guiding input settings based on aspect ratios of original images. (ii) We introduce patch-wise mixup intra-image during ViT patchification (guided by spatial attention scores) and implement uneven stride for better object aspect ratio matching. (iii) We propose a dynamic feature fusing ReID network, enhancing model robustness. Our ReID method achieves a significantly improved mean Average Precision (mAP) of 91.0\% compared to the the closest state-of-the-art (CAL) result of 80.9\% on VehicleID dataset.
翻译:暂无翻译