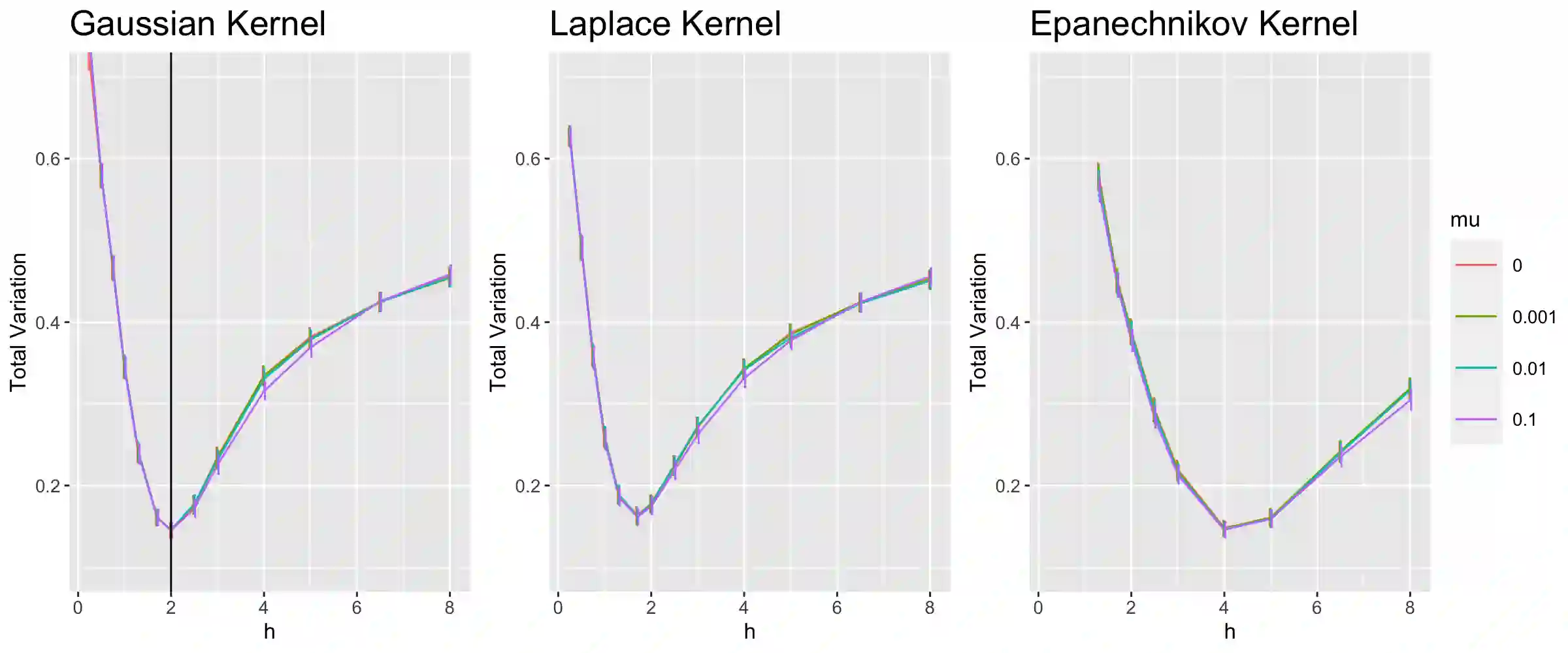
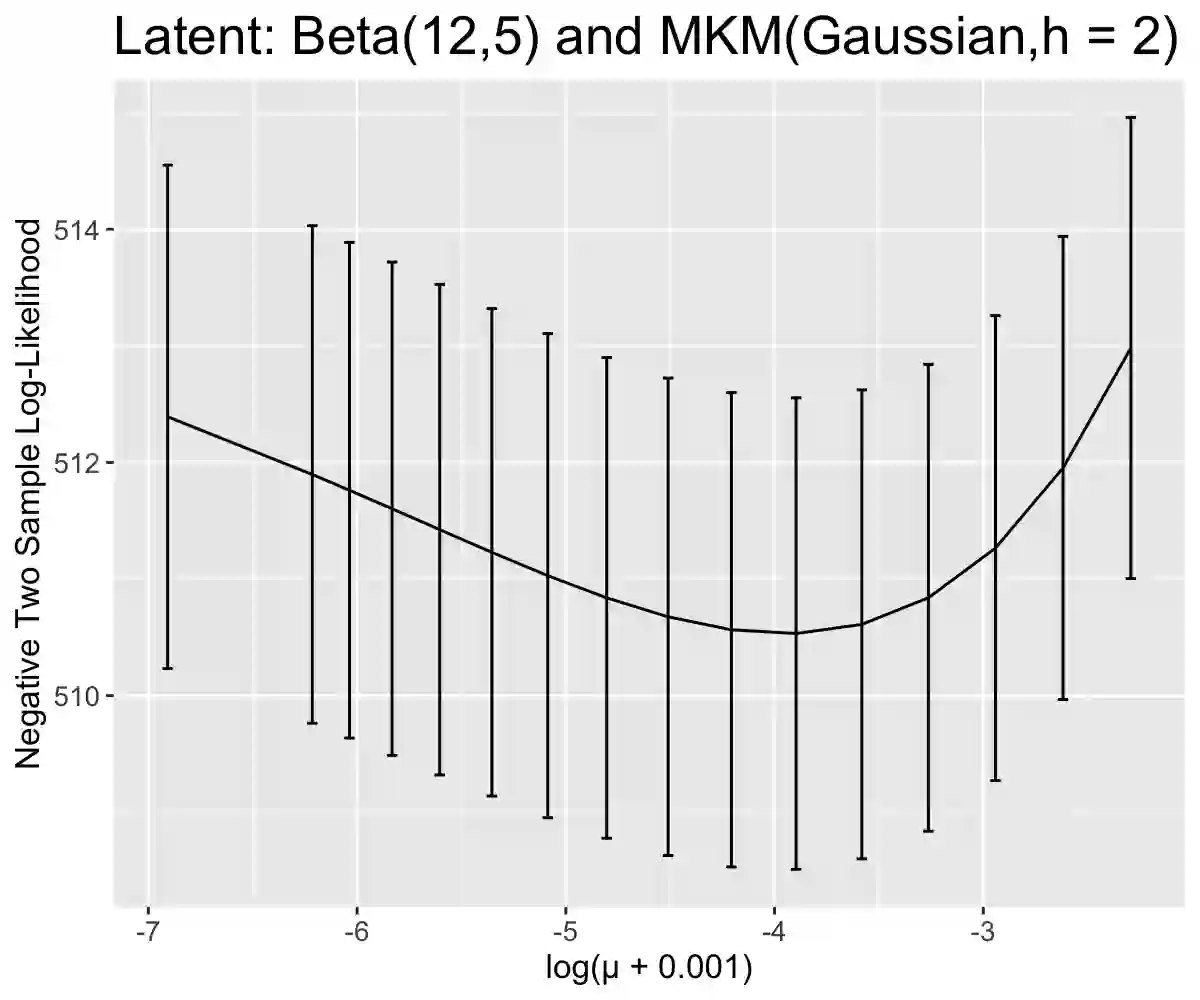
Data harmonization is the process by which an equivalence is developed between two variables measuring a common trait. Our problem is motivated by dementia research in which multiple tests are used in practice to measure the same underlying cognitive ability such as language or memory. We connect this statistical problem to mixing distribution estimation. We introduce and study a non-parametric latent trait model, develop a method which enforces uniqueness of the regularized maximum likelihood estimator, show how a nonparametric EM algorithm will converge weakly to its maximizer, and additionally propose a faster algorithm for learning a discretized approximation of the latent distribution. Furthermore, we develop methods to assess goodness of fit for the mixing likelihood which is an area neglected in most mixing distribution estimation problems. We apply our method to the National Alzheimer's Coordination Center Uniform Data Set and show that we can use our method to convert between score measurements and account for the measurement error. We show that this method outperforms standard techniques commonly used in dementia research. Full code is available at https://github.com/SteveJWR/Data-Harmonization-Nonparametric.
翻译:数据统一是衡量共同特性的两个变量之间形成等值的过程。 我们的问题是痴呆症研究,在实践中使用多种测试来测量语言或内存等同一基本认知能力。 我们将统计问题与混合分布估计联系起来。 我们引入并研究非参数潜在特征模型, 开发一种方法, 以强制实施常规化最大概率估测器的独特性, 显示非参数的EM算法会如何微弱地与最大值相融合, 并另外提出一种更快的算法, 用于学习一种离散的潜值分布近似值。 此外, 我们制定方法, 评估混合可能性的适宜性, 因为在大多数混合分布估计问题中, 该地区被忽略了。 我们将我们的方法应用到全国阿尔茨海默症协调中心的统一数据集, 并表明我们可以使用我们的方法来转换得分测量和计算错误的记分数。 我们显示, 这种方法会超越在dementia研究中常用的标准技术。 在 https://github.com/steveJW/Data-Harmonizt。