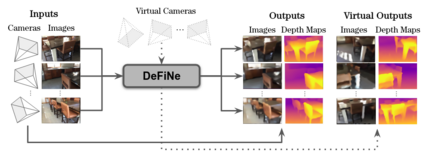
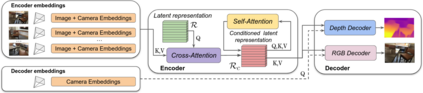
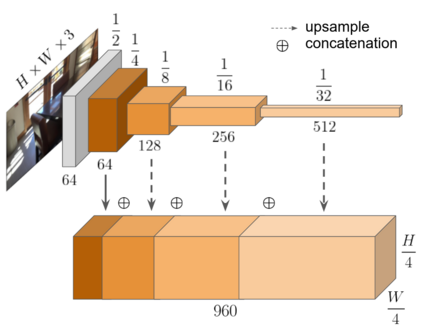
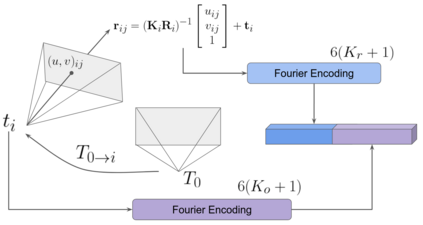
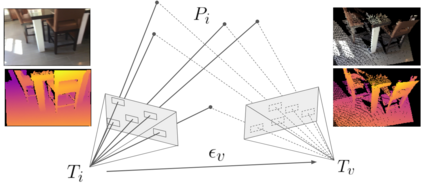
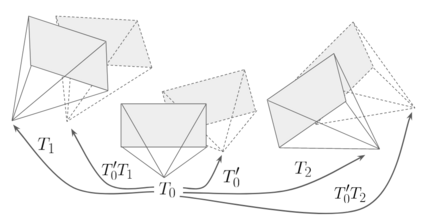
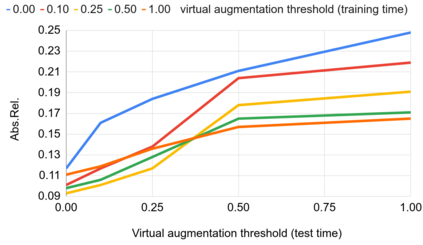
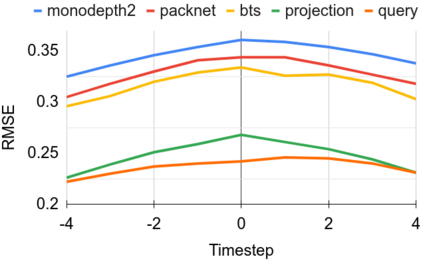
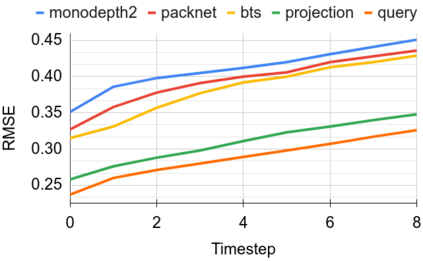
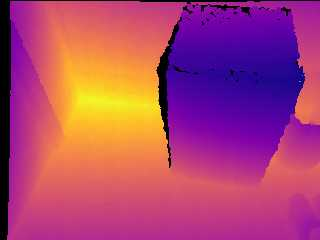
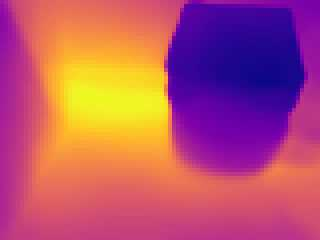
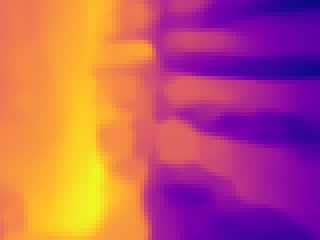
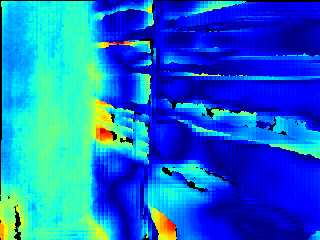
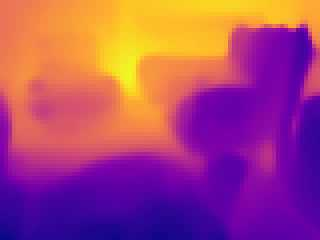
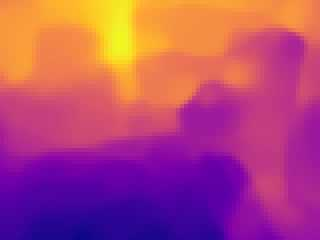
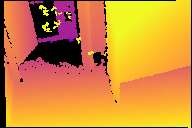
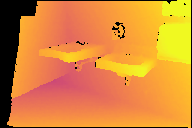
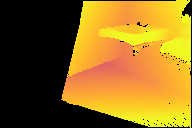
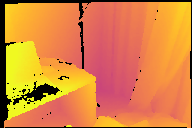
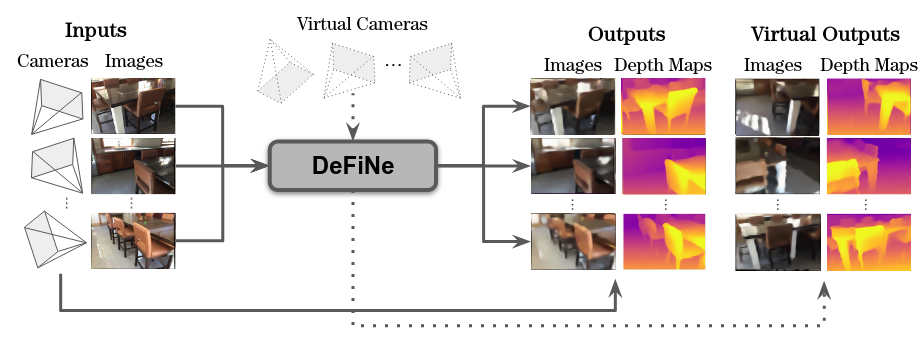
Modern 3D computer vision leverages learning to boost geometric reasoning, mapping image data to classical structures such as cost volumes or epipolar constraints to improve matching. These architectures are specialized according to the particular problem, and thus require significant task-specific tuning, often leading to poor domain generalization performance. Recently, generalist Transformer architectures have achieved impressive results in tasks such as optical flow and depth estimation by encoding geometric priors as inputs rather than as enforced constraints. In this paper, we extend this idea and propose to learn an implicit, multi-view consistent scene representation, introducing a series of 3D data augmentation techniques as a geometric inductive prior to increase view diversity. We also show that introducing view synthesis as an auxiliary task further improves depth estimation. Our Depth Field Networks (DeFiNe) achieve state-of-the-art results in stereo and video depth estimation without explicit geometric constraints, and improve on zero-shot domain generalization by a wide margin.
翻译:现代 3D 计算机愿景利用学习促进几何推理,将图像数据映射到典型结构中,如成本量或上层制约,以改善匹配。这些结构根据特定问题专门设计,因此需要针对特定任务进行重大调整,往往导致低广域化性能。最近,通识式变异器结构在光学流和深度估测等任务中取得了令人印象深刻的成果,通过将几何前程编码为投入,而不是强制约束。在本文件中,我们扩展了这一想法,并提议学习隐含的、多视角一致的场景表示法,采用一系列3D数据增强技术作为几何进式推导法,以增进多样性。我们还表明,引入视觉合成作为辅助任务可以进一步改善深度估测。我们的深度外地网络(DeFiNe)在没有明确的几何限制的情况下,在立体和视频深度估测中取得了最先进的结果,并在宽度上改进零射域的全局化。