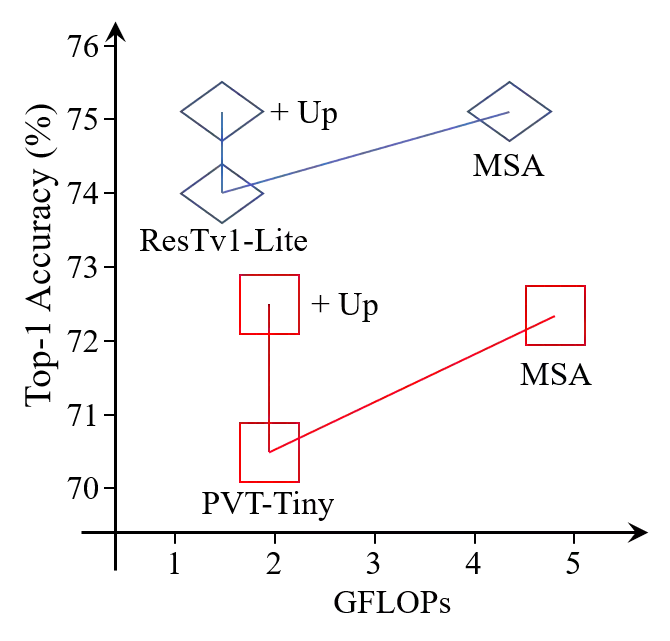
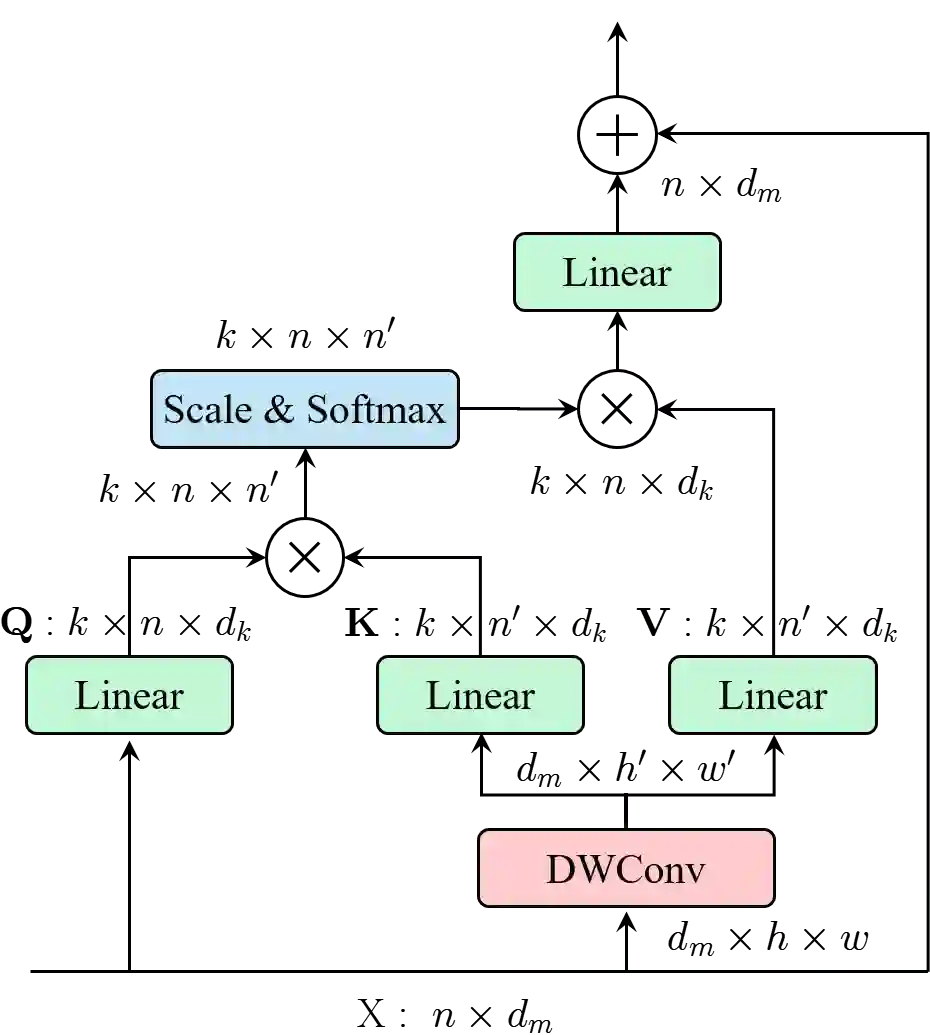
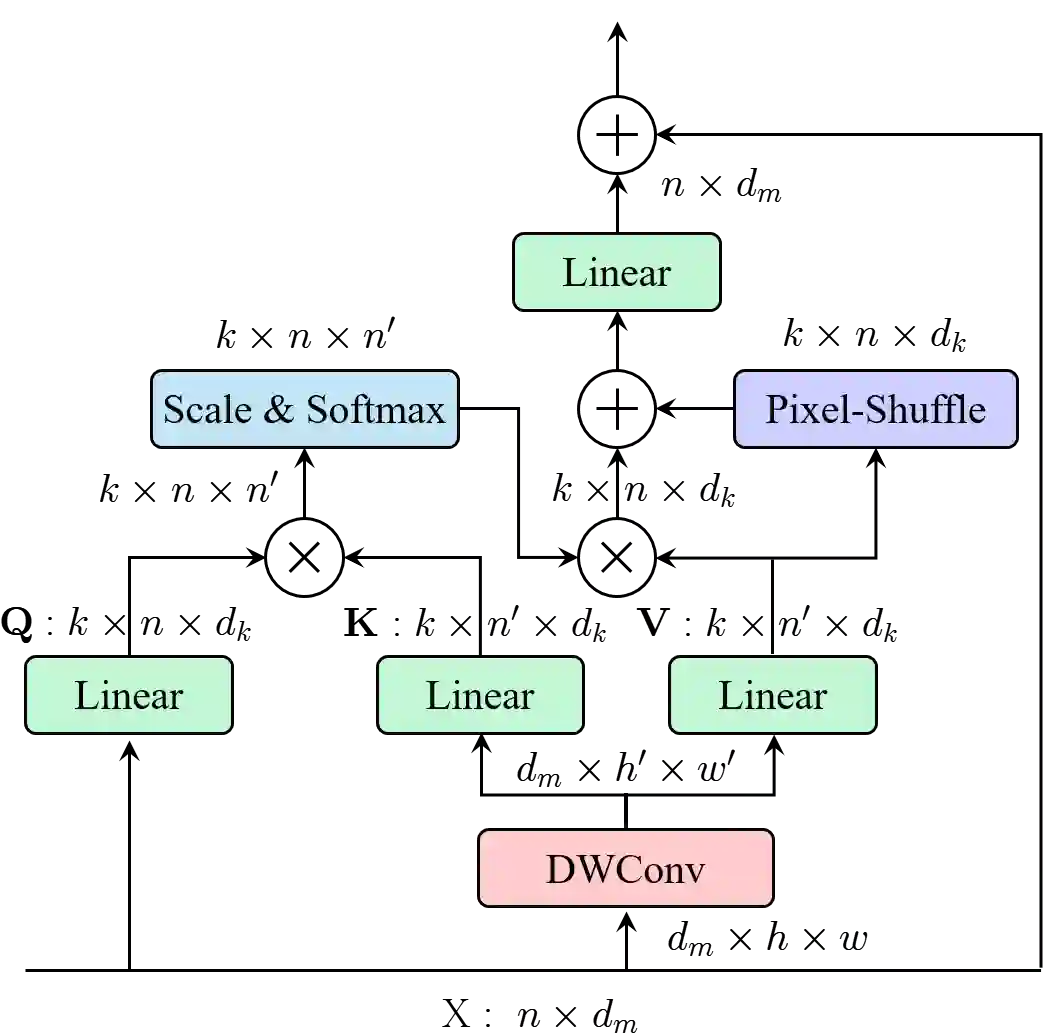
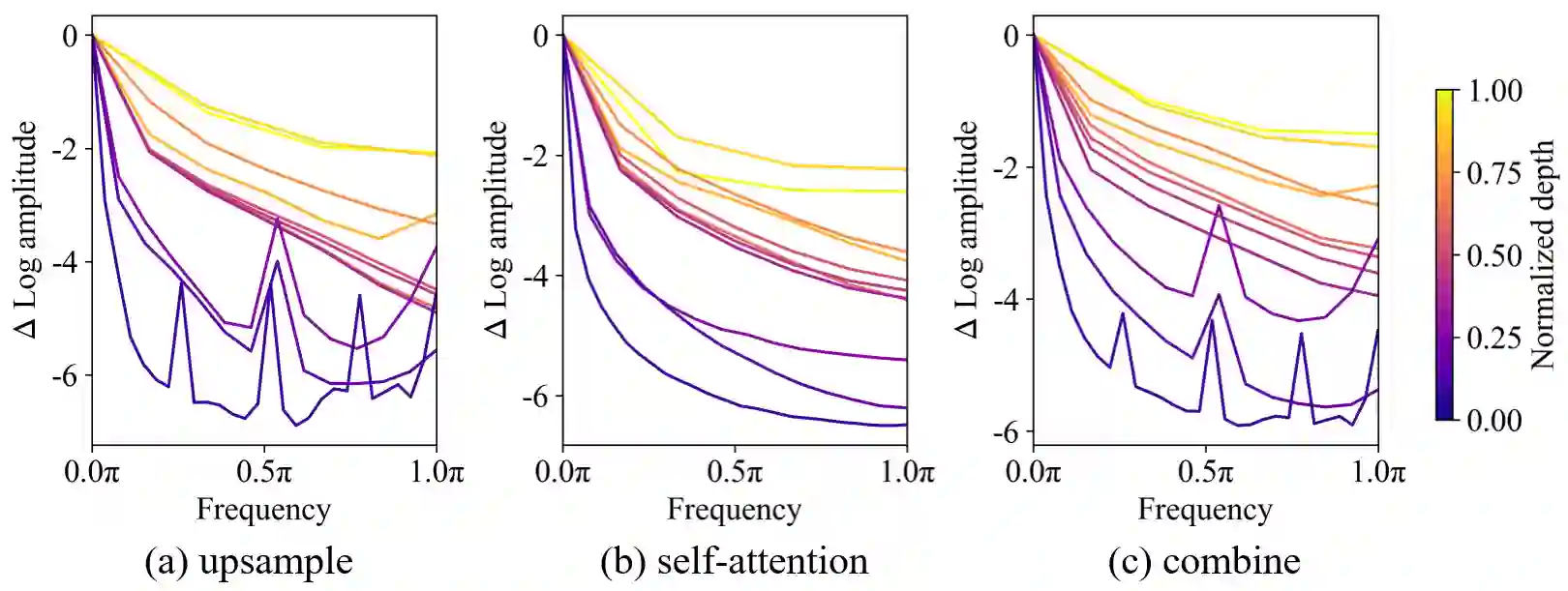
This paper proposes ResTv2, a simpler, faster, and stronger multi-scale vision Transformer for visual recognition. ResTv2 simplifies the EMSA structure in ResTv1 (i.e., eliminating the multi-head interaction part) and employs an upsample operation to reconstruct the lost medium- and high-frequency information caused by the downsampling operation. In addition, we explore different techniques for better apply ResTv2 backbones to downstream tasks. We found that although combining EMSAv2 and window attention can greatly reduce the theoretical matrix multiply FLOPs, it may significantly decrease the computation density, thus causing lower actual speed. We comprehensively validate ResTv2 on ImageNet classification, COCO detection, and ADE20K semantic segmentation. Experimental results show that the proposed ResTv2 can outperform the recently state-of-the-art backbones by a large margin, demonstrating the potential of ResTv2 as solid backbones. The code and models will be made publicly available at \url{https://github.com/wofmanaf/ResT}
翻译:本文建议 ResTv2 是一个更简单、更快、更强的多尺度视觉变形器,用于视觉识别。 ResTv2 简化ResTv1 中的 EMSA 结构( 即消除多头互动部分), 并使用高模操作来重建下取样操作导致的中高频信息。 此外, 我们探索不同技术, 更好地将 ResTv2 脊椎应用到下游任务中。 我们发现, 虽然将 EMSAv2 和窗口关注结合起来, 能够大大降低理论矩阵乘以 FLOP, 但可能会大大降低计算密度, 从而降低实际速度 。 我们全面验证图像网络分类、 COCOCO 检测和 ADE20K 语义分割的 ResTv2 。 实验结果显示, 拟议的 ResTv2 能够以大边距超越最近最先进的脊椎, 表明 ResTv2 作为坚固骨的潜力 。 代码和模型将在\ urlus/ github.com/ wwofmanaf/ResT} 上公布 。