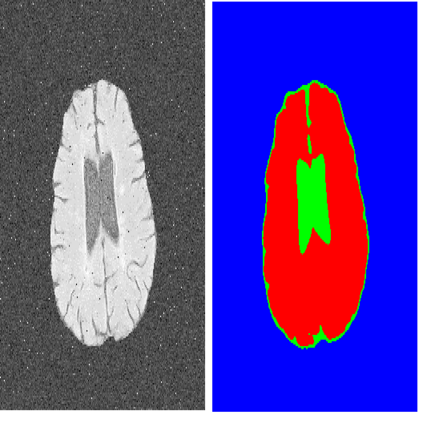
Deep learning has been widely used in medical image segmentation and other aspects. However, the performance of existing medical image segmentation models has been limited by the challenge of obtaining sufficient number of high-quality data with the high cost of data annotation. To overcome the limitation, we propose a new vision-language medical image segmentation model LViT (Language meets Vision Transformer). In our model, medical text annotation is introduced to compensate for the quality deficiency in image data. In addition, the text information can guide the generation of pseudo labels to a certain extent and further guarantee the quality of pseudo labels in semi-supervised learning. We also propose the Exponential Pseudo label Iteration mechanism (EPI) to help extend the semi-supervised version of LViT and the Pixel-Level Attention Module (PLAM) to preserve local features of images. In our model, LV (Language-Vision) loss is designed to supervise the training of unlabeled images using text information directly. To validate the performance of LViT, we construct multimodal medical segmentation datasets (image + text) containing pathological images, X-rays,etc. Experimental results show that our proposed LViT has better segmentation performance in both fully and semi-supervised conditions. Code and datasets are available at https://github.com/HUANGLIZI/LViT.
翻译:深入学习被广泛用于医学图像分割及其他方面,但是,由于难以获得足够数量的高质量数据,且数据注释成本高,现有医学图像分割模型的性能受到限制。为了克服这一限制,我们建议采用新的视力语言医学图像分割模型LViT(语言满足愿景变异器),在我们的模式中,引入医学文本说明,以弥补图像数据的质量缺陷。此外,文本信息可以在某种程度上指导假标签的生成,并进一步保证半监督学习中伪标签的质量。我们还提议采用Expotential Pseudo标签透析机制(EPI),以帮助扩展半超版LViT和Pixel-level 注意模块(PLAM),以维护图像的本地特征。在我们的模式中,LV(语言-Viioniion)损失的目的是直接利用文本信息监督未贴标签图像的培训。为了验证LViT的性能,我们在XiLi-Li-Li分类中构建了多式的医学分类标签标签标签标签标签标签标签标签标签标签标签标签。我们在XILial-Simalseal Dreal 数据集中, 显示我们的拟议实验图象化图象显示更好的结果。