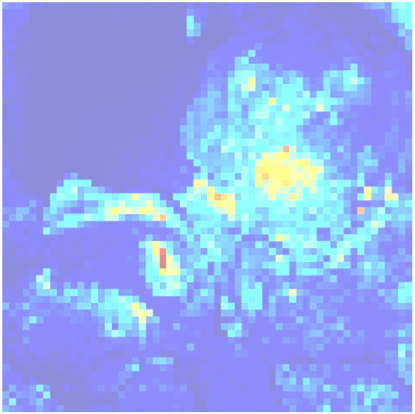
Vision Transformer has demonstrated impressive success across various vision tasks. However, its heavy computation cost, which grows quadratically with respect to the token sequence length, largely limits its power in handling large feature maps. To alleviate the computation cost, previous works rely on either fine-grained self-attentions restricted to local small regions, or global self-attentions but to shorten the sequence length resulting in coarse granularity. In this paper, we propose a novel model, termed as Self-guided Transformer~(SG-Former), towards effective global self-attention with adaptive fine granularity. At the heart of our approach is to utilize a significance map, which is estimated through hybrid-scale self-attention and evolves itself during training, to reallocate tokens based on the significance of each region. Intuitively, we assign more tokens to the salient regions for achieving fine-grained attention, while allocating fewer tokens to the minor regions in exchange for efficiency and global receptive fields. The proposed SG-Former achieves performance superior to state of the art: our base size model achieves \textbf{84.7\%} Top-1 accuracy on ImageNet-1K, \textbf{51.2mAP} bbAP on CoCo, \textbf{52.7mIoU} on ADE20K surpassing the Swin Transformer by \textbf{+1.3\% / +2.7 mAP/ +3 mIoU}, with lower computation costs and fewer parameters. The code is available at \href{https://github.com/OliverRensu/SG-Former}{https://github.com/OliverRensu/SG-Former}
翻译:暂无翻译